Tag Archives: if/else
C++ || Simple Multi Digit, Decimal & Negative Number Infix To Postfix Conversion & Evaluation

The following is sample code which demonstrates the implementation of a multi digit, decimal, and negative number infix to postfix converter and evaluator using C++.
The program demonstrated on this page has the ability to convert and evaluate a single digit, multi digit, decimal number, and/or negative number infix equation. So for example, if the the infix equation of (19.87 * -2) was entered into the program, the converted postfix expression of 19.87 -2 * would display to the screen, as well as the final evaluated answer of -39.74.
REQUIRED KNOWLEDGE FOR THIS PROGRAM
How To Convert Infix To Postfix
How To Evaluate A Postfix Expression
1. Overview
The program demonstrated on this page is different from a previous implementation of the same type in that this version does not use a Finite State Machine during the conversion process, which simplifies the implemetation!
This program has the following flow of control:
• Get an infix expression from the user
• Convert the infix expression to postfix & isolate all of the math operators, multi digit, decimal, negative and single digit numbers that are found in the postfix expression
• Evaluate the postfix expression by breaking the infix string into tokens found from the above step
• Display the evaluated answer to the screen
The above steps are implemented below.
2. Infix To Posfix Conversion & Evaluation
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 |
// ============================================================================ // Author: Kenneth Perkins // Date: Jan 31, 2014 // Updated: Feb 5, 2021 // Taken From: http://programmingnotes.org/ // File: InToPostEval.cpp // Description: The following demonstrates the implementation of an infix to // postfix converter and evaluator. This program has the ability to // convert and evaluate multi digit, decimal, negative and positive values // ============================================================================ #include <iostream> #include <cstdlib> #include <cmath> #include <cctype> #include <string> #include <vector> #include <stack> #include <algorithm> #include <exception> #include <stdexcept> // function prototypes void displayDirections(); std::string convertInfixToPostfix(std::string infix); bool isMathOperator(char token); int orderOfOperations(char token); double evaluatePostfix(const std::string& postfix); double calculate(char mathOperator, double value1, double value2); bool isNumeric(char value); bool isNumeric(std::string value); std::vector<std::string> split(const std::string& source, const std::string& delimiters = " "); std::string replaceAll(const std::string& source , const std::string& oldValue, const std::string& newValue); int main() { // declare variables std::string infix = ""; // display directions to user displayDirections(); try { // get data from user std::cout << "\nPlease enter an Infix expression: "; std::getline(std::cin, infix); // convert infix to postfix std::string postfix = convertInfixToPostfix(infix); std::cout << "\nThe Infix expression = " << infix; std::cout << "\nThe Postfix expression = " << postfix << std::endl; // evaluate the postfix string double answer = evaluatePostfix(postfix); std::cout << "\nFinal answer = " << answer << std::endl; } catch (std::exception& e) { std::cout << "\nAn error occurred: " + std::string(e.what()) << std::endl; } std::cin.get(); return 0; }// end of main void displayDirections() { // this function displays instructions to the screen std::cout << "\n==== Infix To Postfix Conversion & Evaluation ====\n" << "\nMath Operators:\n" << "+ || Addition\n" << "- || Subtraction\n" << "* || Multiplication\n" << "/ || Division\n" << "% || Modulus\n" << "^ || Power\n" << "$ || Square Root\n" << "s || Sine\n" << "c || Cosine\n" << "t || Tangent\n" << "- || Negative Number\n" << "Sample Infix Equation: ((s(-4^5)*1.4)/($(23+2)--2.8))*(c(1%2)/(7.28*.1987)^(t23))\n"; // ((sin(-4^5)*1.4)/(sqrt(23+2)--2.8))*(cos(1%2)/(7.28*.1987)^(tan(23))) }// end of displayDirections std::string convertInfixToPostfix(std::string infix) { // this function converts an infix expression to postfix // declare function variables std::string postfix; std::stack<char> charStack; // remove all whitespace from the string infix.erase(std::remove_if(infix.begin(), infix.end(), [](char c) { return std::isspace(static_cast<unsigned char>(c)); }), infix.end()); // negate equations marked with '--' infix = replaceAll(infix, "(--", "("); // automatically convert negative numbers to have the ~ symbol. // this is done so we can distinguish negative numbers and the subtraction symbol for (unsigned x = 0; x < infix.length(); ++x) { if (infix[x] != '-') { continue; } if (x == 0 || infix[x - 1] == '(' || isMathOperator(infix[x - 1])) { infix[x] = '~'; } } // loop thru array until there is no more data for (unsigned x = 0; x < infix.length(); ++x) { // place numbers (standard, decimal, & negative) // numbers onto the 'postfix' string if (isNumeric(infix[x])) { if (postfix.length() > 0 && !isNumeric(postfix.back())) { if (!std::isspace(postfix.back())) { postfix += " "; } } postfix += infix[x]; } else if (std::isspace(infix[x])) { continue; } else if (isMathOperator(infix[x])) { if (postfix.length() > 0 && !std::isspace(postfix.back())) { postfix += " "; } // use the 'orderOfOperations' function to check equality // of the math operator at the top of the stack compared to // the current math operator in the infix string while ((!charStack.empty()) && (orderOfOperations(charStack.top()) >= orderOfOperations(infix[x]))) { // place the math operator from the top of the // stack onto the postfix string and continue the // process until complete if (postfix.length() > 0 && !std::isspace(postfix.back())) { postfix += " "; } postfix += charStack.top(); charStack.pop(); } // push the remaining math operator onto the stack charStack.push(infix[x]); } // push outer parentheses onto stack else if (infix[x] == '(') { charStack.push(infix[x]); } else if (infix[x] == ')') { // pop the current math operator from the stack while ((!charStack.empty()) && (charStack.top() != '(')) { if (postfix.length() > 0 && !std::isspace(postfix.back())) { postfix += " "; } // place the math operator onto the postfix string postfix += charStack.top(); // pop the next operator from the stack and // continue the process until complete charStack.pop(); } // pop '(' symbol off the stack if (!charStack.empty()) { charStack.pop(); } else { // no matching '(' throw std::invalid_argument{ "PARENTHESES MISMATCH" }; } } else { throw std::invalid_argument{ "INVALID INPUT" }; } } // place any remaining math operators from the stack onto // the postfix array while (!charStack.empty()) { if (charStack.top() == '(' || charStack.top() == ')') { throw std::invalid_argument{ "PARENTHESES MISMATCH" }; } if (postfix.length() > 0 && !std::isspace(postfix.back())) { postfix += " "; } postfix += charStack.top(); charStack.pop(); } // replace all '~' symbols with a minus sign postfix = replaceAll(postfix, "~", "-"); return postfix; }// end of convertInfixToPostfix bool isMathOperator(char token) { // this function checks if operand is a math operator switch (std::tolower(token)) { case '+': case '-': case '*': case '/': case '%': case '^': case '$': case 'c': case 's': case 't': return true; break; default: return false; break; } }// end of isMathOperator int orderOfOperations(char token) { // this function returns the priority of each math operator int priority = 0; switch (std::tolower(token)) { case 'c': case 's': case 't': priority = 5; break; case '^': case '$': priority = 4; break; case '*': case '/': case '%': priority = 3; break; case '-': priority = 2; break; case '+': priority = 1; break; } return priority; }// end of orderOfOperations double evaluatePostfix(const std::string& postfix) { // this function evaluates a postfix expression // declare function variables double answer = 0; std::stack<double> doubleStack; // split string into tokens to isolate multi digit, negative and decimal // numbers, aswell as single digit numbers and math operators auto tokens = split(postfix); // display the found tokens to the screen //for (unsigned x = 0; x < tokens.size(); ++x) { // std::cout<< tokens.at(x) << std::endl; //} std::cout << "\nCalculations:\n"; // loop thru array until there is no more data for (unsigned x = 0; x < tokens.size(); ++x) { auto token = tokens[x]; // push numbers & negative numbers onto the stack if (isNumeric(token)) { doubleStack.push(std::atof(token.c_str())); } // if expression is a math operator, pop numbers from stack // & send the popped numbers to the 'calculate' function else if (isMathOperator(token[0]) && (!doubleStack.empty())) { double value1 = 0; double value2 = 0; char mathOperator = static_cast<unsigned char>(std::tolower(token[0])); // if expression is square root, sin, cos, // or tan operation only pop stack once if (mathOperator == '$' || mathOperator == 's' || mathOperator == 'c' || mathOperator == 't') { value2 = 0; value1 = doubleStack.top(); doubleStack.pop(); answer = calculate(mathOperator, value1, value2); doubleStack.push(answer); } else if (doubleStack.size() > 1) { value2 = doubleStack.top(); doubleStack.pop(); value1 = doubleStack.top(); doubleStack.pop(); answer = calculate(mathOperator, value1, value2); doubleStack.push(answer); } } else { // this should never execute, & if it does, something went really wrong throw std::invalid_argument{ "INVALID POSTFIX STRING" }; } } // pop the final answer from the stack, and return to main if (!doubleStack.empty()) { answer = doubleStack.top(); } return answer; }// end of evaluatePostfix double calculate(char mathOperator, double value1, double value2) { // this function carries out the actual math process double ans = 0; switch (std::tolower(mathOperator)) { case '+': std::cout << value1 << mathOperator << value2; ans = value1 + value2; break; case '-': std::cout << value1 << mathOperator << value2; ans = value1 - value2; break; case '*': std::cout << value1 << mathOperator << value2; ans = value1 * value2; break; case '/': std::cout << value1 << mathOperator << value2; ans = value1 / value2; break; case '%': std::cout << value1 << mathOperator << value2; ans = ((int)value1 % (int)value2) + std::modf(value1, &value2); break; case '^': std::cout << value1 << mathOperator << value2; ans = std::pow(value1, value2); break; case '$': std::cout << char(251) << value1; ans = std::sqrt(value1); break; case 'c': std::cout << "cos(" << value1 << ")"; ans = std::cos(value1); break; case 's': std::cout << "sin(" << value1 << ")"; ans = std::sin(value1); break; case 't': std::cout << "tan(" << value1 << ")"; ans = std::tan(value1); break; default: ans = 0; break; } std::cout << " = " << ans << std::endl; return ans; }// end of calculate std::vector<std::string> split(const std::string& source, const std::string& delimiters) { std::size_t prev = 0; std::size_t currentPos = 0; std::vector<std::string> results; while ((currentPos = source.find_first_of(delimiters, prev)) != std::string::npos) { if (currentPos > prev) { results.push_back(source.substr(prev, currentPos - prev)); } prev = currentPos + 1; } if (prev < source.length()) { results.push_back(source.substr(prev, std::string::npos)); } return results; }// end of split std::string replaceAll(const std::string& source , const std::string& oldValue, const std::string& newValue) { if (oldValue.empty()) { return source; } std::string newString; newString.reserve(source.length()); std::size_t lastPos = 0; std::size_t findPos; while (std::string::npos != (findPos = source.find(oldValue, lastPos))) { newString.append(source, lastPos, findPos - lastPos); newString += newValue; lastPos = findPos + oldValue.length(); } newString += source.substr(lastPos); return newString; }// end of replaceAll bool isNumeric(char value) { return std::isdigit(value) || value == '.' || value == '~'; }// end of isNumeric bool isNumeric(std::string value) { for (unsigned index = 0; index < value.length(); ++index) { if (index == 0 && value[index] == '-' && value.length() > 1) { continue; } if (!isNumeric(value[index])) { return false; } } return true; }// http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
The following is sample output.
====== RUN 1 ======
==== Infix To Postfix Conversion & Evaluation ====
Math Operators:
+ || Addition
- || Subtraction
* || Multiplication
/ || Division
% || Modulus
^ || Power
$ || Square Root
s || Sine
c || Cosine
t || Tangent
- || Negative Number
Sample Infix Equation: ((s(-4^5)*1.4)/($(23+2)--2.8))*(c(1%2)/(7.28*.1987)^(t23))Please enter an Infix expression: 12/3*9
The Infix expression = 12/3*9
The Postfix expression = 12 3 / 9 *Calculations:
12/3 = 4
4*9 = 36Final answer = 36
====== RUN 2 ======
==== Infix To Postfix Conversion & Evaluation ====
Math Operators:
+ || Addition
- || Subtraction
* || Multiplication
/ || Division
% || Modulus
^ || Power
$ || Square Root
s || Sine
c || Cosine
t || Tangent
- || Negative Number
Sample Infix Equation: ((s(-4^5)*1.4)/($(23+2)--2.8))*(c(1%2)/(7.28*.1987)^(t23))Please enter an Infix expression: -150.89996 - 87.56643
The Infix expression = -150.89996 - 87.56643
The Postfix expression = -150.89996 87.56643 -Calculations:
-150.9-87.5664 = -238.466Final answer = -238.466
====== RUN 3 ======
==== Infix To Postfix Conversion & Evaluation ====
Math Operators:
+ || Addition
- || Subtraction
* || Multiplication
/ || Division
% || Modulus
^ || Power
$ || Square Root
s || Sine
c || Cosine
t || Tangent
- || Negative Number
Sample Infix Equation: ((s(-4^5)*1.4)/($(23+2)--2.8))*(c(1%2)/(7.28*.1987)^(t23))Please enter an Infix expression: ((s(-4^5)*1.4)/($(23+2)--2.8))*(c(1%2)/(7.28*.1987)^(t23))
The Infix expression = ((s(-4^5)*1.4)/($(23+2)--2.8))*(c(1%2)/(7.28*.1987)^(t23))
The Postfix expression = -4 5 ^ s 1.4 * 23 2 + $ -2.8 - / 1 2 % c 7.28 .1987 * 23 t ^ / *Calculations:
-4^5 = -1024
sin(-1024) = 0.158533
0.158533*1.4 = 0.221947
23+2 = 25
√25 = 5
5--2.8 = 7.8
0.221947/7.8 = 0.0284547
1%2 = 1
cos(1) = 0.540302
7.28*0.1987 = 1.44654
tan(23) = 1.58815
1.44654^1.58815 = 1.79733
0.540302/1.79733 = 0.300614
0.0284547*0.300614 = 0.00855389Final answer = 0.00855389
====== RUN 4 ======
==== Infix To Postfix Conversion & Evaluation ====
Math Operators:
+ || Addition
- || Subtraction
* || Multiplication
/ || Division
% || Modulus
^ || Power
$ || Square Root
s || Sine
c || Cosine
t || Tangent
- || Negative Number
Sample Infix Equation: ((s(-4^5)*1.4)/($(23+2)--2.8))*(c(1%2)/(7.28*.1987)^(t23))Please enter an Infix expression: (1987 + 1991) * -1
The Infix expression = (1987 + 1991) * -1
The Postfix expression = 1987 1991 + -1 *Calculations:
1987+1991 = 3978
3978*-1 = -3978Final answer = -3978
====== RUN 5 ======
==== Infix To Postfix Conversion & Evaluation ====
Math Operators:
+ || Addition
- || Subtraction
* || Multiplication
/ || Division
% || Modulus
^ || Power
$ || Square Root
s || Sine
c || Cosine
t || Tangent
- || Negative Number
Sample Infix Equation: ((s(-4^5)*1.4)/($(23+2)--2.8))*(c(1%2)/(7.28*.1987)^(t23))Please enter an Infix expression: (1+(2*((3+(4*5))*6)))
The Infix expression = (1+(2*((3+(4*5))*6)))
The Postfix expression = 1 2 3 4 5 * + 6 * * +Calculations:
4*5 = 20
3+20 = 23
23*6 = 138
2*138 = 276
1+276 = 277Final answer = 277
C++ || Multi Digit, Decimal & Negative Number Infix To Postfix Conversion & Evaluation
The following is sample code which demonstrates the implementation of a multi digit, decimal, and negative number infix to postfix converter and evaluator using a Finite State Machine
REQUIRED KNOWLEDGE FOR THIS PROGRAM
How To Convert Infix To Postfix
How To Evaluate A Postfix Expression
What Is A Finite State Machine?
Using a Finite State Machine, the program demonstrated on this page has the ability to convert and evaluate a single digit, multi digit, decimal number, and/or negative number infix equation. So for example, if the the infix equation of (19.87 * -2) was entered into the program, the converted postfix expression of 19.87 ~2* would display to the screen, as well as the final evaluated answer of -39.74.
NOTE: In this program, negative numbers are represented by the “~” symbol on the postfix string. This is used to differentiate between a negative number and a subtraction symbol.
This program has the following flow of control:
• Get an infix expression from the user
• Convert the infix expression to postfix
• Use a Finite State Machine to isolate all of the math operators, multi digit, decimal, negative and single digit numbers that are found in the postfix expression
• Evaluate the postfix expression using the tokens found from the above step
• Display the evaluated answer to the screen
The above steps are implemented below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 |
// ============================================================================ // Author: Kenneth Perkins // Taken From: http://programmingnotes.org/ // Date: Jan 31, 2014 // File: InToPostEval.cpp // Description: The following demonstrates the implementation of an infix to // postfix converter and evaluator. Using a Finite State Machine, this // program has the ability to convert and evaluate multi digit, decimal, // negative and positive values. // ============================================================================ #include <iostream> #include <cstdlib> #include <cmath> #include <cctype> #include <string> #include <vector> #include <stack> #include <algorithm> using namespace std; /* This holds the transition states for our Finite State Machine -- They are placed in numerical order for easy understanding within the FSM array, which is located below */ enum FSM_TRANSITIONS { REJECT = 0, INTEGER, REAL, NEGATIVE, OPERATOR, UNKNOWN, SPACE }; /* This is the Finite State Machine -- The zero represents a place holder, so the row in the array starts on row 1 instead of 0 integer, real, negative, operator, unknown, space */ int stateTable[][7] = { {0, INTEGER, REAL, NEGATIVE, OPERATOR, UNKNOWN, SPACE}, /* STATE 1 */ {INTEGER, INTEGER, REAL, REJECT, REJECT, REJECT, REJECT}, /* STATE 2 */ {REAL, REAL, REJECT, REJECT, REJECT, REJECT, REJECT}, /* STATE 3 */ {NEGATIVE, INTEGER, REAL, REJECT, REJECT, REJECT, REJECT}, /* STATE 4 */ {OPERATOR, REJECT, REJECT, REJECT, REJECT, REJECT, REJECT}, /* STATE 5 */ {UNKNOWN, REJECT, REJECT, REJECT, REJECT, UNKNOWN, REJECT}, /* STATE 6 */ {SPACE, REJECT, REJECT, REJECT, REJECT, REJECT, REJECT} }; // function prototypes void DisplayDirections(); string ConvertInfixToPostfix(string infix); bool IsMathOperator(char token); int OrderOfOperations(char token); vector<string> Lexer(string postfix); int Get_FSM_Col(char& currentChar); double EvaluatePostfix(const vector<string>& postfix); double Calculate(char token, double op1, double op2); int main() { // declare variables string infix = ""; string postfix = ""; double answer = 0; vector<string> tokens; // display directions to user DisplayDirections(); // get data from user cout << "\nPlease enter an Infix expression: "; getline(cin, infix); postfix = ConvertInfixToPostfix(infix); // use the "Lexer" function to isolate multi digit, negative and decimal // numbers, aswell as single digit numbers and math operators tokens = Lexer(postfix); // display the found tokens to the screen //for (unsigned x = 0; x < tokens.size(); ++x) //{ // cout<<tokens.at(x)<<endl; //} cout << "\nThe Infix expression = " << infix; cout << "\nThe Postfix expression = " << postfix << endl; answer = EvaluatePostfix(tokens); cout << "\nFinal answer = " << answer << endl; cin.get(); return 0; }// end of main void DisplayDirections() {// this function displays instructions to the screen cout << "\n==== Infix To Postfix Conversion & Evaluation ====\n" << "\nMath Operators:\n" << "+ || Addition\n" << "- || Subtraction\n" << "* || Multiplication\n" << "/ || Division\n" << "% || Modulus\n" << "^ || Power\n" << "$ || Square Root\n" << "s || Sine\n" << "c || Cosine\n" << "t || Tangent\n" << "- || Negative Number\n" << "Sample Infix Equation: ((s(-4^5)*1.4)/($(23+2)--2.8))*(c(1%2)/(7.28*.1987)^(t23))\n"; // ((sin(-4^5)*1.4)/(sqrt(23+2)--2.8))*(cos(1%2)/(7.28*.1987)^(tan(23))) }// end of DisplayDirections string ConvertInfixToPostfix(string infix) {// this function converts an infix expression to postfix // declare function variables string postfix; stack<char> charStack; // remove all whitespace from the string infix.erase(std::remove_if(infix.begin(), infix.end(), [](char c) { return std::isspace(static_cast<unsigned char>(c)); }), infix.end()); // automatically convert negative numbers to have the ~ symbol for (unsigned x = 0; x < infix.length(); ++x) { if (infix[x] != '-') { continue; } else if (x + 1 < infix.length() && IsMathOperator(infix[x + 1])) { continue; } if (x == 0 || infix[x - 1] == '(' || IsMathOperator(infix[x - 1])) { infix[x] = '~'; } } // loop thru array until there is no more data for (unsigned x = 0; x < infix.length(); ++x) { // place numbers (standard, decimal, & negative) // numbers onto the 'postfix' string if ((isdigit(infix[x])) || (infix[x] == '.') || (infix[x] == '~')) { postfix += infix[x]; } else if (isspace(infix[x])) { continue; } else if (IsMathOperator(infix[x])) { postfix += " "; // use the 'OrderOfOperations' function to check equality // of the math operator at the top of the stack compared to // the current math operator in the infix string while ((!charStack.empty()) && (OrderOfOperations(charStack.top()) >= OrderOfOperations(infix[x]))) { // place the math operator from the top of the // stack onto the postfix string and continue the // process until complete postfix += charStack.top(); charStack.pop(); } // push the remaining math operator onto the stack charStack.push(infix[x]); } // push outer parentheses onto stack else if (infix[x] == '(') { charStack.push(infix[x]); } else if (infix[x] == ')') { // pop the current math operator from the stack while ((!charStack.empty()) && (charStack.top() != '(')) { // place the math operator onto the postfix string postfix += charStack.top(); // pop the next operator from the stack and // continue the process until complete charStack.pop(); } if (!charStack.empty()) // pop '(' symbol off the stack { charStack.pop(); } else // no matching '(' { cout << "\nPARENTHESES MISMATCH #1\n"; exit(1); } } else { cout << "\nINVALID INPUT #1\n"; exit(1); } } // place any remaining math operators from the stack onto // the postfix array while (!charStack.empty()) { postfix += charStack.top(); charStack.pop(); } return postfix; }// end of ConvertInfixToPostfix bool IsMathOperator(char token) {// this function checks if operand is a math operator switch (tolower(token)) { case '+': case '-': case '*': case '/': case '%': case '^': case '$': case 'c': case 's': case 't': return true; break; default: return false; break; } }// end of IsMathOperator int OrderOfOperations(char token) {// this function returns the priority of each math operator int priority = 0; switch (tolower(token)) { case 'c': case 's': case 't': priority = 5; break; case '^': case '$': priority = 4; break; case '*': case '/': case '%': priority = 3; break; case '-': priority = 2; break; case '+': priority = 1; break; } return priority; }// end of OrderOfOperations vector<string> Lexer(string postfix) {// this function parses a postfix string using an FSM to generate // each individual token in the expression vector<string> tokens; char currentChar = ' '; int col = REJECT; int currentState = REJECT; string currentToken = ""; // use an FSM to parse multidigit and decimal numbers // also does error check for invalid input of decimals for (unsigned x = 0; x < postfix.length();) { currentChar = postfix[x]; // get the column number for the current character col = Get_FSM_Col(currentChar); // exit if the real number has multiple periods "." // in the expression (i.e: 19.3427.23) if ((currentState == REAL) && (col == REAL)) { cerr << "\nINVALID INPUT #2\n"; exit(1); } /* ======================================================== THIS IS WHERE WE CHECK THE FINITE STATE MACHINE TABLE USING THE "col" VARIABLE FROM ABOVE ^ ========================================================= */ // get the current state of our machine currentState = stateTable[currentState][col]; /* =================================================== THIS IS WHERE WE CHECK FOR A SUCCESSFUL PARSE - If the current state in our machine == REJECT (the starting state), then we have successfully parsed a token, which is returned to its caller - ELSE we continue trying to find a successful token =================================================== */ if (currentState == REJECT) { if (currentToken != " ") // we dont care about whitespace { tokens.push_back(currentToken); } currentToken = ""; } else { currentToken += currentChar; ++x; } } // this ensures the last token gets saved when // we reach the end of the postfix string buffer if (currentToken != " ") // we dont care about whitespace { tokens.push_back(currentToken); } return tokens; }// end of Lexer int Get_FSM_Col(char& currentChar) {// this function determines the state of the type of character being examined // check for whitespace if (isspace(currentChar)) { return SPACE; } // check for integer numbers else if (isdigit(currentChar)) { return INTEGER; } // check for real numbers else if (currentChar == '.') { return REAL; } // check for negative numbers else if (currentChar == '~') { currentChar = '-'; return NEGATIVE; } // check for math operators else if (IsMathOperator(currentChar)) { return OPERATOR; } return UNKNOWN; }// end of Get_FSM_Col double EvaluatePostfix(const vector<string>& postfix) {// this function evaluates a postfix expression // declare function variables double op1 = 0; double op2 = 0; double answer = 0; stack<double> doubleStack; cout << "\nCalculations:\n"; // loop thru array until there is no more data for (unsigned x = 0; x < postfix.size(); ++x) { // push numbers onto the stack if ((isdigit(postfix[x][0])) || (postfix[x][0] == '.')) { doubleStack.push(atof(postfix[x].c_str())); } // push negative numbers onto the stack else if ((postfix[x].length() > 1) && ((postfix[x][0] == '-') && (isdigit(postfix[x][1]) || (postfix[x][1] == '.')))) { doubleStack.push(atof(postfix[x].c_str())); } // if expression is a math operator, pop numbers from stack // & send the popped numbers to the 'Calculate' function else if (IsMathOperator(postfix[x][0]) && (!doubleStack.empty())) { char token = tolower(postfix[x][0]); // if expression is square root, sin, cos, // or tan operation only pop stack once if (token == '$' || token == 's' || token == 'c' || token == 't') { op2 = 0; op1 = doubleStack.top(); doubleStack.pop(); answer = Calculate(token, op1, op2); doubleStack.push(answer); } else if (doubleStack.size() > 1) { op2 = doubleStack.top(); doubleStack.pop(); op1 = doubleStack.top(); doubleStack.pop(); answer = Calculate(token, op1, op2); doubleStack.push(answer); } } else // this should never execute, & if it does, something went really wrong { cout << "\nINVALID INPUT #3\n"; exit(1); } } // pop the final answer from the stack, and return to main if (!doubleStack.empty()) { answer = doubleStack.top(); } return answer; }// end of EvaluatePostfix double Calculate(char token, double op1, double op2) {// this function carries out the actual math process double ans = 0; switch (tolower(token)) { case '+': cout << op1 << token << op2 << " = "; ans = op1 + op2; break; case '-': cout << op1 << token << op2 << " = "; ans = op1 - op2; break; case '*': cout << op1 << token << op2 << " = "; ans = op1 * op2; break; case '/': cout << op1 << token << op2 << " = "; ans = op1 / op2; break; case '%': cout << op1 << token << op2 << " = "; ans = ((int)op1 % (int)op2) + modf(op1, &op2); break; case '^': cout << op1 << token << op2 << " = "; ans = pow(op1, op2); break; case '$': cout << char(251) << op1 << " = "; ans = sqrt(op1); break; case 'c': cout << "cos(" << op1 << ") = "; ans = cos(op1); break; case 's': cout << "sin(" << op1 << ") = "; ans = sin(op1); break; case 't': cout << "tan(" << op1 << ") = "; ans = tan(op1); break; default: ans = 0; break; } cout << ans << endl; return ans; }// http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
The following is sample output.
====== RUN 1 ======
==== Infix To Postfix Conversion & Evaluation ====Math Operators:
+ || Addition
- || Subtraction
* || Multiplication
/ || Division
% || Modulus
^ || Power
$ || Square Root
s || Sine
c || Cosine
t || Tangent
~ || Negative NumberSample Infix Equation: ((s(~4^5)*1.4)/($(23+2)-~2.8))*(c(1%2)/(7.28*.1987)^(t23))
Please enter an Infix expression: 12/3*9
The Infix expression = 12/3*9
The Postfix expression = 12 3 /9*Calculations:
12/3 = 4
4*9 = 36Final answer = 36
====== RUN 2 ======
==== Infix To Postfix Conversion & Evaluation ====
Math Operators:
+ || Addition
- || Subtraction
* || Multiplication
/ || Division
% || Modulus
^ || Power
$ || Square Root
s || Sine
c || Cosine
t || Tangent
~ || Negative NumberSample Infix Equation: ((s(~4^5)*1.4)/($(23+2)-~2.8))*(c(1%2)/(7.28*.1987)^(t23))
Please enter an Infix expression: -150.89996 - 87.56643
The Infix expression = -150.89996 - 87.56643
The Postfix expression = ~150.89996 87.56643-Calculations:
-150.9-87.5664 = -238.466Final answer = -238.466
====== RUN 3 ======
==== Infix To Postfix Conversion & Evaluation ====
Math Operators:
+ || Addition
- || Subtraction
* || Multiplication
/ || Division
% || Modulus
^ || Power
$ || Square Root
s || Sine
c || Cosine
t || Tangent
~ || Negative NumberSample Infix Equation: ((s(~4^5)*1.4)/($(23+2)-~2.8))*(c(1%2)/(7.28*.1987)^(t23))
Please enter an Infix expression: ((s(~4^5)*1.4)/($(23+2)-~2.8))*(c(1%2)/(7.28*.1987)^(t23))
The Infix expression = ((s(-4^5)*1.4)/($(23+2)--2.8))*(c(1%2)/(7.28*.1987)^(t23))
The Postfix expression = ~4 5^ s1.4* 23 2+ $~2.8-/ 1 2% c7.28 .1987* 23t^/*Calculations:
-4^5 = -1024
sin(-1024) = 0.158533
0.158533*1.4 = 0.221947
23+2 = 25
√25 = 5
5--2.8 = 7.8
0.221947/7.8 = 0.0284547
1%2 = 1
cos(1) = 0.540302
7.28*0.1987 = 1.44654
tan(23) = 1.58815
1.44654^1.58815 = 1.79733
0.540302/1.79733 = 0.300614
0.0284547*0.300614 = 0.00855389Final answer = 0.00855389
====== RUN 4 ======
==== Infix To Postfix Conversion & Evaluation ====
Math Operators:
+ || Addition
- || Subtraction
* || Multiplication
/ || Division
% || Modulus
^ || Power
$ || Square Root
s || Sine
c || Cosine
t || Tangent
- || Negative Number
Sample Infix Equation: ((s(-4^5)*1.4)/($(23+2)--2.8))*(c(1%2)/(7.28*.1987)^(t23))Please enter an Infix expression: (1987 + 1991) * -1
The Infix expression = (1987 + 1991) * -1
The Postfix expression = 1987 1991+ ~1*Calculations:
1987+1991 = 3978
3978*-1 = -3978Final answer = -3978
Python || Find The Average Using A List – Omit Highest And Lowest Scores

This page will consist of a program which calculates the average of a specific amount of numbers using a list.
REQUIRED KNOWLEDGE FOR THIS PROGRAM
Lists
For Loops
Arithmetic Operators
Basic Math - How To Find The Average
The following program is fairly simple, and was used to introduce the list concept. This program prompts the user to enter the total amount of numbers they wish to find the average for, then displays the answer to the screen. Using a sort, this program also has the ability to find the average of a list of numbers, omitting the highest and lowest valued items.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
# ============================================================================= # Author: K Perkins # Taken From: http://programmingnotes.org/ # Date: Jan 29, 2014 # File: Average.py # Description: The following demonstrates finding the average of numbers # contained in a list. # ============================================================================= # calculate the average of numbers in a list def Average(arry, size): total = 0 # traverse the list adding all the items together for x in range(size): total += arry[x] # return the average return total / size ## end of Average def main(): # declare variables arry = [] # initialize the list numElems = 0 # ask user how many items they want to place in list numElems = int(input("How many items do you want to place into the list?: ")) # print a newline print("") # user enters data into list using a for loop for x in range(0, numElems): arry.append(int(input("Enter item #%d: " % (x+1)))) # display data print("nThe current items inside the list are: ") for x in range(0, numElems): print("Item #%d: %d" % ((x+1), arry[x])) # display the average using a function print("nThe average of the %d numbers is %.2f" % (numElems, Average(arry, len(arry)))) # sort the numbers in the list from lowest to highest arry.sort() # erase the highest/lowest numbers arry.pop(len(arry)-1) arry.pop(0) # display the average using a function print("nThe average adjusted score omitting the highest and " "lowest result is %.2f" % (Average(arry, len(arry)))) ## end of main if __name__ == "__main__": main() # http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
The following is sample output.
How many items do you want to place into the list?: 5Enter item #1: 7
Enter item #2: 7
Enter item #3: 4
Enter item #4: 8
Enter item #5: 7The current items inside the list are:
Item #1: 7
Item #2: 7
Item #3: 4
Item #4: 8
Item #5: 7The average of the 5 numbers is 6.60
The average adjusted score omitting the highest and lowest result is 7.00
C++ || Custom Template Hash Map With Iterator Using Separate Chaining

Before we get into the code, what is a Hash Map? Simply put, a Hash Map is an extension of a Hash Table; which is a data structure used to map unique “keys” to specific “values.” The Hash Map demonstrated on this page is different from the previous Hash Table implementation in that key/value pairs do not need to be the same datatype, they can be completely different. So for example, if you wish to map a string “key” to an integer “value“, utilizing a Hash Map is ideal.
In its most simplest form, a Hash Map can be thought of as an associative array, or a “dictionary.” Hash Map’s are composed of a collection of key/value pairs, such that each possible key appears atleast once in the collection for a given value. While a standard array requires that indice subscripts be integers, a hash map can use a string, an integer, or even a floating point value as the index. That index is called the “key,” and the contents within the array at that specific index location is called the “value.” A hash map uses a hash function to generate an index into the table, creating buckets or slots, from which the correct value can be found.
To illustrate, suppose that you’re working with some data that has values associated with strings — for instance, you might have student names and you wish to assign them grades. How would you store this data? Depending on your skill level, you might use multiple arrays during the implementation. For example, in terms of a one dimensional array, if we wanted to access the data for a student located at index #25, we could access it by doing:
studentNames[25]; // do something with the data
studentGrades[25];
Here, we dont have to search through each element in the array to find what we need, we just access it at index #25. The question is, how do we know that index #25 holds the data that we are looking for? If we have a large set of data, not only will keeping track of multiple arrays become tiresome, but doing a sequential search over each item within the separate arrays can become very inefficient. That is where hashing comes in handy. Using a Hash Map, we can use the students name as the “key,” and the students grade as the data “value.” Given this “key” (the students name), we can apply a hash function to map a unique index or bucket within the hash table to find the data “value” (the students grade) that we wish to access.
So in essence, a Hash Map is an extension of a hash table, which is a data structure that stores key/value pairs. Hash tables are typically used because they are ideal for doing a quick search of items.
Though hashing is ideal, it isnt perfect. It is possible for multiple “keys” to be hashed into the same location. Hash “collisions” are practically unavoidable when hashing large data sets. The code demonstrated on this page handles collisions via separate chaining, utilizing an array of linked list head nodes to store multiple keys within one bucket – should any collisions occur.
A special feature of this current hash map class is that its implemented as a multimap, meaning that more than one “value” can be associated with a given “key.” For example, in a student enrollment system where students may be enrolled in multiple classes simultaneously, there might be an association for each enrollment where the “key” is the student ID, and the “value” is the course ID. In this example, if a given student is enrolled in three courses, there will be three associated “values” (course ID’s) for one “key” (student ID) in the Hash Map.
An iterator was also implemented, making data access that much more simple within the hash map class. Click here for an overview demonstrating how custom iterators can be built.
=== CUSTOM TEMPLATE HASH MAP WITH ITERATOR ===
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 |
// ============================================================================ // Author: Kenneth Perkins // Date: June 11, 2013 // Taken From: http://programmingnotes.org/ // File: HashMap.h // Description: This is a class which implements various functions // demonstrating the use of a Hash Map. // ============================================================================ #ifndef TEMPLATE_HASH_MAP #define TEMPLATE_HASH_MAP #include <iostream> #include <string> #include <sstream> #include <cstdlib> // if user doesnt define, this is the // default hash map size const int HASH_SIZE = 350; template <class Key, class Value> class HashMap { public: HashMap(int hashSze = HASH_SIZE); /* Function: Constructor initializes hash map Precondition: None Postcondition: Defines private variables */ bool IsEmpty(int keyIndex); /* Function: Determines whether hash map is empty at the given hash map key index Precondition: Hash map has been created Postcondition: The function = true if the hash map is empty and the function = false if hash map is not empty */ bool IsFull(); /* Function: Determines whether hash map is full Precondition: Hash map has been created Postcondition: The function = true if the hash map is full and the function = false if hash map is not full */ int Hash(Key m_key); /* Function: Computes and returns a hash map key index for a given item The returned key index is the given cell where the item resides Precondition: Hash map has been created and is not full Postcondition: The hash key is returned */ void Insert(Key m_key, Value m_value); /* Function: Adds new item to the back of the list at a given key in the hash map A unique hash key is automatically generated for each new item Precondition: Hash map has been created and is not full Postcondition: Item is in the hash map */ bool Remove(Key m_key, Value deleteItem); /* Function: Removes the first instance from the map whose value is "deleteItem" Precondition: Hash map has been created and is not empty Postcondition: The function = true if deleteItem is found and the function = false if deleteItem is not found */ void Sort(int keyIndex); /* Function: Sort the items in the map at the given hashmap key index Precondition: Hash map has been initialized Postcondition: The hash map is sorted */ int TableSize(); /* Function: Return the size of the hash map Precondition: Hash map has been initialized Postcondition: The size of the hash map is returned */ int TotalElems(); /* Function: Return the total number of elements contained in the hash map Precondition: Hash map has been initialized Postcondition: The size of the hash map is returned */ int BucketSize(int keyIndex); /* Function: Return the number of items contained in the hash map cell at the given hashmap key index Precondition: Hash map has been initialized Postcondition: The size of the given key cell is returned */ int Count(Key m_key, Value searchItem); /* Function: Return the number of times searchItem appears in the map at the given key Precondition: Hash map has been initialized Postcondition: The number of times searchItem appears in the map is returned */ int ContainsKey(Key m_key); /* Function: Return the number of times the given key appears in the hashmap Precondition: Hash map has been initialized Postcondition: The number of times the given key appears in the map is returned */ void MakeEmpty(); /* Function: Initializes hash map to an empty state Precondition: Hash map has been created Postcondition: Hash map no longer exists */ ~HashMap(); /* Function: Removes the hash map Precondition: Hash map has been declared Postcondition: Hash map no longer exists */ // -- ITERATOR CLASS -- class Iterator; /* Function: Class declaration to the iterator Precondition: Hash map has been declared Postcondition: Hash Iterator has been declared */ Iterator begin(int keyIndex){return(!IsEmpty(keyIndex)) ? head[keyIndex]:NULL;} /* Function: Returns the beginning of the current hashmap key index Precondition: Hash map has been declared Postcondition: Hash cell has been returned to the Iterator */ Iterator end(int keyIndex=0){return NULL;} /* Function: Returns the end of the current hashmap key index Precondition: Hash map has been declared Postcondition: Hash cell has been returned to the Iterator */ private: struct KeyValue // struct to hold key/value pairs { Key key; Value value; }; struct node { KeyValue currentItem; node* next; }; node** head; // array of linked list declaration - front of each hash map cell int hashSize; // the size of the hash map (how many cells it has) int totElems; // holds the total number of elements in the entire table int* bucketSize; // holds the total number of elems in each specific hash map cell }; //========================= Implementation ================================// template <class Key, class Value> HashMap<Key, Value>::HashMap(int hashSze) { hashSize = hashSze; head = new node*[hashSize]; bucketSize = new int[hashSize]; for(int x=0; x < hashSize; ++x) { head[x] = NULL; bucketSize[x] = 0; } totElems = 0; }/* End of HashMap */ template <class Key, class Value> bool HashMap<Key, Value>::IsEmpty(int keyIndex) { if(keyIndex >=0 && keyIndex < hashSize) { return head[keyIndex] == NULL; } return true; }/* End of IsEmpty */ template <class Key, class Value> bool HashMap<Key, Value>::IsFull() { try { node* location = new node; delete location; return false; } catch(std::bad_alloc&) { return true; } }/* End of IsFull */ template <class Key, class Value> int HashMap<Key, Value>::Hash(Key m_key) { long h = 19937; std::stringstream convert; // convert the parameter to a string using "stringstream" which is done // so we can hash multiple datatypes using only one function convert << m_key; std::string temp = convert.str(); for(unsigned x=0; x < temp.length(); ++x) { h = (h << 6) ^ (h >> 26) ^ temp[x]; } return abs(h % hashSize); } /* End of Hash */ template <class Key, class Value> void HashMap<Key, Value>::Insert(Key m_key, Value m_value) { if(IsFull()) { //std::cout<<"\nINSERT ERROR - HASH MAP FULL\n"; } else { int keyIndex = Hash(m_key); node* newNode = new node; // add new node newNode-> currentItem.key = m_key; newNode-> currentItem.value = m_value; newNode-> next = NULL; if(IsEmpty(keyIndex)) { head[keyIndex] = newNode; } else { node* temp = head[keyIndex]; while(temp-> next != NULL) { temp = temp-> next; } temp-> next = newNode; } ++bucketSize[keyIndex]; ++totElems; } }/* End of Insert */ template <class Key, class Value> bool HashMap<Key, Value>::Remove(Key m_key, Value deleteItem) { bool isFound = false; node* temp; int keyIndex = Hash(m_key); if(IsEmpty(keyIndex)) { //std::cout<<"\nREMOVE ERROR - HASH MAP EMPTY\n"; } else if(head[keyIndex]->currentItem.key == m_key && head[keyIndex]->currentItem.value == deleteItem) { temp = head[keyIndex]; head[keyIndex] = head[keyIndex]-> next; delete temp; --totElems; --bucketSize[keyIndex]; isFound = true; } else { for(temp = head[keyIndex];temp->next!=NULL;temp=temp->next) { if(temp->next->currentItem.key == m_key && temp->next->currentItem.value == deleteItem) { node* deleteNode = temp->next; temp-> next = temp-> next-> next; delete deleteNode; isFound = true; --totElems; --bucketSize[keyIndex]; break; } } } return isFound; }/* End of Remove */ template <class Key, class Value> void HashMap<Key, Value>::Sort(int keyIndex) { if(IsEmpty(keyIndex)) { //std::cout<<"\nSORT ERROR - HASH MAP EMPTY\n"; } else { int listSize = BucketSize(keyIndex); bool sorted = false; do{ sorted = true; int x = 0; for(node* temp = head[keyIndex]; temp->next!=NULL && x < listSize-1; temp=temp->next,++x) { if(temp-> currentItem.value > temp->next->currentItem.value) { std::swap(temp-> currentItem,temp->next->currentItem); sorted = false; } } --listSize; }while(!sorted); } }/* End of Sort */ template <class Key, class Value> int HashMap<Key, Value>::TableSize() { return hashSize; }/* End of TableSize */ template <class Key, class Value> int HashMap<Key, Value>::TotalElems() { return totElems; }/* End of TotalElems */ template <class Key, class Value> int HashMap<Key, Value>::BucketSize(int keyIndex) { return(!IsEmpty(keyIndex)) ? bucketSize[keyIndex]:0; }/* End of BucketSize */ template <class Key, class Value> int HashMap<Key, Value>::Count(Key m_key, Value searchItem) { int keyIndex = Hash(m_key); int search = 0; if(IsEmpty(keyIndex)) { //std::cout<<"\nCOUNT ERROR - HASH MAP EMPTY\n"; } else { for(node* temp = head[keyIndex];temp!=NULL;temp=temp->next) { if(temp->currentItem.key == m_key && temp->currentItem.value == searchItem) { ++search; } } } return search; }/* End of Count */ template <class Key, class Value> int HashMap<Key, Value>::ContainsKey(Key m_key) { int keyIndex = Hash(m_key); int search = 0; if(IsEmpty(keyIndex)) { //std::cout<<"\nCONTAINS KEY ERROR - HASH MAP EMPTY\n"; } else { for(node* temp = head[keyIndex];temp!=NULL;temp=temp->next) { if(temp->currentItem.key == m_key) { ++search; } } } return search; }/* End of ContainsKey */ template <class Key, class Value> void HashMap<Key, Value>::MakeEmpty() { totElems = 0; for(int x=0; x < hashSize; ++x) { if(!IsEmpty(x)) { //std::cout << "Destroying nodes ...\n"; while(!IsEmpty(x)) { node* temp = head[x]; //std::cout << temp-> currentItem.value <<std::endl; head[x] = head[x]-> next; delete temp; } } bucketSize[x] = 0; } }/* End of MakeEmpty */ template <class Key, class Value> HashMap<Key, Value>::~HashMap() { MakeEmpty(); delete[] head; delete[] bucketSize; }/* End of ~HashMap */ // END OF THE HASH MAP CLASS // ----------------------------------------------------------- // START OF THE HASH MAP ITERATOR CLASS template <class Key, class Value> class HashMap<Key, Value>::Iterator : public std::iterator<std::forward_iterator_tag,Value>, public HashMap<Key, Value> { public: // Iterator constructor Iterator(node* otherIter = NULL) { itHead = otherIter; } ~Iterator() {} // The assignment and relational operators are straightforward Iterator& operator=(const Iterator& other) { itHead = other.itHead; return(*this); } bool operator==(const Iterator& other)const { return itHead == other.itHead; } bool operator!=(const Iterator& other)const { return itHead != other.itHead; } bool operator<(const Iterator& other)const { return itHead < other.itHead; } bool operator>(const Iterator& other)const { return other.itHead < itHead; } bool operator<=(const Iterator& other)const { return (!(other.itHead < itHead)); } bool operator>=(const Iterator& other)const { return (!(itHead < other.itHead)); } // Update my state such that I refer to the next element in the // HashMap. Iterator operator+(int incr) { node* temp = itHead; for(int x=0; x < incr && temp!= NULL; ++x) { temp = temp->next; } return temp; } Iterator operator+=(int incr) { for(int x=0; x < incr && itHead!= NULL; ++x) { itHead = itHead->next; } return itHead; } Iterator& operator++() // pre increment { if(itHead != NULL) { itHead = itHead->next; } return(*this); } Iterator operator++(int) // post increment { node* temp = itHead; this->operator++(); return temp; } KeyValue& operator[](int incr) { // Return "junk" data // to prevent the program from crashing if(itHead == NULL || (*this + incr) == NULL) { return junk; } return(*(*this + incr)); } // Return a reference to the value in the node. I do this instead // of returning by value so a caller can update the value in the // node directly. KeyValue& operator*() { // Return "junk" data // to prevent the program from crashing if(itHead == NULL) { return junk; } return itHead->currentItem; } KeyValue* operator->() { return(&**this); } private: node* itHead; KeyValue junk; }; #endif // http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The iterator class starts on line #381, and is built to support most of the standard relational operators, as well as arithmetic operators such as ‘+,+=,++’ (pre/post increment). The * (star), bracket [] and -> arrow operators are also supported. Click here for an overview demonstrating how custom iterators can be built.
The rest of the code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
===== DEMONSTRATION HOW TO USE =====
Use of the above template class is the same as many of its STL template class counterparts. Here are sample programs demonstrating its use.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 |
// DEMONSTRATE BASIC USE AND THE REMOVE / SORT FUNCTIONS #include <iostream> #include <string> #include "HashMap.h" using namespace std; // iterator declaration typedef HashMap<string, int>::Iterator iterDec; int main() { // declare variables HashMap<string, int> hashMap; // place items into the hash map using the 'insert' function // NOTE: its OK for dupicate keys to be inserted into the hash map hashMap.Insert("BIOL", 585); hashMap.Insert("CPSC", 386); hashMap.Insert("ART", 101); hashMap.Insert("CPSC", 462); hashMap.Insert("HIST", 251); hashMap.Insert("CPSC", 301); hashMap.Insert("MATH", 270); hashMap.Insert("PE", 145); hashMap.Insert("BIOL", 134); hashMap.Insert("GEOL", 201); hashMap.Insert("CIS", 465); hashMap.Insert("CPSC", 240); hashMap.Insert("GEOL", 101); hashMap.Insert("MATH", 150); hashMap.Insert("DANCE", 134); hashMap.Insert("CPSC", 131); hashMap.Insert("ART", 345); hashMap.Insert("CHEM", 185); hashMap.Insert("PE", 125); hashMap.Insert("CPSC", 120); // display the number of times the key "CPSC" appears in the hashmap cout<<"The key 'CPSC' appears in the hash map "<< hashMap.ContainsKey("CPSC")<<" time(s)\n"; // declare an iterator for the "CPSC" key so we can display data to screen iterDec it = hashMap.begin(hashMap.Hash("CPSC")); // display the first value cout<<"\nThe first item with the key 'CPSC' is: " <<it[0].value<<endl; // display all the values in the hash map whose key matches "CPSC" // NOTE: its possible for multiple different keys types // to be placed into the same hash map bucket cout<<"\nThese are all the items in the hash map whose key is 'CPSC': \n"; for(int x=0; x < hashMap.BucketSize(hashMap.Hash("CPSC")); ++x) { if(it[x].key == "CPSC") // make sure this is the key we are looking for { cout<<" Key-> "<<it[x].key<<"\tValue-> "<<it[x].value<<endl; } } // remove the first value from the key "CPSC" cout<<"\n[REMOVE THE VALUE '"<<it[0].value<<"' FROM THE KEY '"<<it[0].key<<"']\n"; hashMap.Remove("CPSC",it[0].value); // display the number of times the key "CPSC" appears in the hashmap cout<<"\nNow the key 'CPSC' only appears in the hash map "<< hashMap.ContainsKey("CPSC")<<" time(s)\n"; // update the iterator to the current hash map state it = hashMap.begin(hashMap.Hash("CPSC")); // sort the values in the hash map bucket whose key is "CSPC" hashMap.Sort(hashMap.Hash("CPSC")); // display the values whose key matches "CPSC" cout<<"\nThese are the sorted items in the hash map whose key is 'CPSC': \n"; for(int x=0; x < hashMap.BucketSize(hashMap.Hash("CPSC")); ++x) { if(it[x].key == "CPSC") { cout<<" Key-> "<<it[x].key<<"\tValue-> "<<it[x].value<<endl; } } // display all the key/values in the entire hash map cout<<"\nThese are all of the items in the entire hash map: \n"; for(int x=0; x < hashMap.TableSize(); ++x) { if(!hashMap.IsEmpty(x)) { for(iterDec iter = hashMap.begin(x); iter != hashMap.end(x); ++iter) { cout<<" Key-> "<<(*iter).key<<"\tValue-> "<<iter->value<<endl; } cout<<endl; } } // display the total number of items in the hash map cout<<"The total number of items in the hash map is: "<< hashMap.TotalElems()<<endl; return 0; }// http://programmingnotes.org/ |
SAMPLE OUTPUT:
The key 'CPSC' appears in the hash map 6 time(s)The first item with the key 'CPSC' is: 386
These are all the items in the hash map whose key is 'CPSC':
Key-> CPSC Value-> 386
Key-> CPSC Value-> 462
Key-> CPSC Value-> 301
Key-> CPSC Value-> 240
Key-> CPSC Value-> 131
Key-> CPSC Value-> 120[REMOVE THE VALUE '386' FROM THE KEY 'CPSC']
Now the key 'CPSC' only appears in the hash map 5 time(s)
These are the sorted items in the hash map whose key is 'CPSC':
Key-> CPSC Value-> 120
Key-> CPSC Value-> 131
Key-> CPSC Value-> 240
Key-> CPSC Value-> 301
Key-> CPSC Value-> 462These are all of the items in the entire hash map:
Key-> CIS Value-> 465Key-> DANCE Value-> 134
Key-> PE Value-> 145
Key-> PE Value-> 125Key-> MATH Value-> 270
Key-> MATH Value-> 150Key-> GEOL Value-> 201
Key-> GEOL Value-> 101Key-> CPSC Value-> 120
Key-> CPSC Value-> 131
Key-> CPSC Value-> 240
Key-> CPSC Value-> 301
Key-> CPSC Value-> 462Key-> BIOL Value-> 585
Key-> BIOL Value-> 134Key-> ART Value-> 101
Key-> ART Value-> 345Key-> CHEM Value-> 185
Key-> HIST Value-> 251
The total number of items in the hash map is: 19
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 |
// DISPLAY ALL DATA INSIDE HASH MAP USING STD::STRING / INT / DOUBLE / STRUCT #include <iostream> #include <string> #include "HashMap.h" using namespace std; // sample struct demo struct MyStruct { string car; int year; double mpg; // struct comparison operators // used for 'remove' function bool operator == (const MyStruct& rhs)const { return car == rhs.car && year == rhs.year && mpg == rhs.mpg; } // used for 'sort' function bool operator > (const MyStruct& rhs)const { return car > rhs.car; } };// end of MyStruct // iterator declaration typedef HashMap<string, MyStruct>::Iterator iterDec; int main() { // declare variables MyStruct access; HashMap<string, MyStruct> hashMap(10); // --- initialize data for car #1 --- access.car = "Ford Fusion"; access.year = 2006; access.mpg = 28.5; hashMap.Insert("Kenneth",access); // --- initialize data for car #2 --- access.car = "BMW 535i"; access.year = 2014; access.mpg = 25.4; hashMap.Insert("Kenneth",access); // --- initialize data for car #3 --- access.car = "Nissan Altima"; access.year = 2011; access.mpg = 30.7; hashMap.Insert("Jessica",access); // --- initialize data for car #4 --- access.car = "Acura Integra"; access.year = 2001; access.mpg = 20.2; hashMap.Insert("Kenneth",access); // diplay how many cars "Kenneth" owns cout <<"'Kenneth' owns "<<hashMap.ContainsKey("Kenneth")<<" cars"<<endl; // display all items in the hash map // NOTE: its possible for multiple different keys types // to be placed into the same hash map bucket cout<<"\nThese are all of the cars in the hash map: \n"; for(int x=0; x < hashMap.TableSize(); ++x) { if(!hashMap.IsEmpty(x)) { // initialize an iterator iterDec iter = hashMap.begin(x); // display the key cout<<(*iter).key<<"'s car(s)\n"; // display all the values for(;iter != hashMap.end(x); ++iter) { cout<<"\tCar: "<<iter->value.car <<"\n\tYear: "<<iter->value.year <<"\n\tMPG: "<<iter->value.mpg<<endl<<endl; } } } // display the number of items in the hash map cout<<"The total number of cars in the hash map is: "<< hashMap.TotalElems()<<endl; // sort the cars that "Kenneth" owns by name cout<<"\nSorting the cars that 'Kenneth' owns by name.. \n"; hashMap.Sort(hashMap.Hash("Kenneth")); // display all items in the hash map again cout<<"\nAgain, these are all of the cars in the hash map: \n"; for(int x=0; x < hashMap.TableSize(); ++x) { if(!hashMap.IsEmpty(x)) { // initialize an iterator iterDec iter = hashMap.begin(x); // display the key cout<<iter->key<<"'s car(s)\n"; // display all the values for(;iter != hashMap.end(x); ++iter) { cout<<"\tCar: "<<(*iter).value.car <<"\n\tYear: "<<(*iter).value.year <<"\n\tMPG: "<<(*iter).value.mpg<<endl<<endl; } } } // remove the car 'Acura Integra' from "Kenneth's" inventory for(iterDec iter = hashMap.begin(hashMap.Hash("Kenneth")); iter != hashMap.end(hashMap.Hash("Kenneth")); ++iter) { if(iter->value.car == "Acura Integra") { cout<<"'"<<iter->value.car<<"' has been removed from 'Kenneth's' inventory..\n"; hashMap.Remove("Kenneth",(*iter).value); break; } } // display how many cars "Kenneth" owns cout <<"\n'Kenneth' now owns only "<<hashMap.ContainsKey("Kenneth")<<" cars"<<endl; // display all items in the hash map one more time cout<<"\nThese are all of the cars in the hash map with the 'Acura Integra' removed: \n"; for(int x=0; x < hashMap.TableSize(); ++x) { if(!hashMap.IsEmpty(x)) { // initialize an iterator iterDec iter = hashMap.begin(x); // display the key cout<<(*iter).key<<"'s car(s)\n"; // display all the values for(;iter != hashMap.end(x); ++iter) { cout<<"\tCar: "<<iter->value.car <<"\n\tYear: "<<iter->value.year <<"\n\tMPG: "<<iter->value.mpg<<endl<<endl; } } } // display the number of items in the hash map cout<<"The total number of cars in the hash map is: "<< hashMap.TotalElems()<<endl; return 0; }// http://programmingnotes.org/ |
SAMPLE OUTPUT:
'Kenneth' owns 3 carsThese are all of the cars in the hash map:
Jessica's car(s)
Car: Nissan Altima
Year: 2011
MPG: 30.7Kenneth's car(s)
Car: Ford Fusion
Year: 2006
MPG: 28.5Car: BMW 535i
Year: 2014
MPG: 25.4Car: Acura Integra
Year: 2001
MPG: 20.2
-----------------------------------------------------The total number of cars in the hash map is: 4
Sorting the cars that 'Kenneth' owns by name..
Again, these are all of the cars in the hash map:
Jessica's car(s)
Car: Nissan Altima
Year: 2011
MPG: 30.7Kenneth's car(s)
Car: Acura Integra
Year: 2001
MPG: 20.2Car: BMW 535i
Year: 2014
MPG: 25.4Car: Ford Fusion
Year: 2006
MPG: 28.5
-----------------------------------------------------'Acura Integra' has been removed from 'Kenneth's' inventory..
'Kenneth' now owns only 2 cars
These are all of the cars in the hash map with the 'Acura Integra' removed:
Jessica's car(s)
Car: Nissan Altima
Year: 2011
MPG: 30.7Kenneth's car(s)
Car: BMW 535i
Year: 2014
MPG: 25.4Car: Ford Fusion
Year: 2006
MPG: 28.5
-----------------------------------------------------The total number of cars in the hash map is: 3
Python || Using If Statements & String Variables

As previously mentioned, you can use “int” and “float” to represent numbers, but what if you want to store letters? Strings help you do that.
==== SINGLE CHAR ====
This example will demonstrate a simple program using strings, which checks to see if the user entered the correctly predefined letter.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# ============================================================================= # Author: Kenneth Perkins # Date: May 29, 2013 # Updated: Feb 16, 2021 # Taken From: http://programmingnotes.org/ # File: char.py # Description: Demonstrates using char variables # ============================================================================= def main(): # declare variables userInput = "" # this variable is a string letter = '' # this holds the individual character # get data from user userInput = input("Please try to guess the letter I am thinking of: ") # we only want to check the first character in the string, # so we get the letter at index zero and save it into its # own variable letter = userInput[0] # use an if statement to check equality. if ((letter == 'a') or (letter == 'A')): print("\nYou have guessed correctly!") else: print("\nSorry, that was not the correct letter I was thinking of..") if __name__ == "__main__": main() # http://programmingnotes.org/ |
Notice in line 11 I declare the string data type, naming it “userInput.” I also initialized it as an empty variable. In line 23 I used an “If/Else Statement” to determine if the user entered value matches the predefined letter within the program. I also used the “OR” operator in line 23 to determine if the letter the user entered into the program was lower or uppercase. Try compiling the program simply using this
if (letter == 'a') as your if statement, and notice the difference.
The resulting code should give this as output
Please try to guess the letter I am thinking of: A
You have guessed correctly!
==== CHECK IF LETTER IS UPPER CASE ====
This example is similar to the previous one, and will check if a user entered letter is uppercase.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# ============================================================================= # Author: Kenneth Perkins # Date: May 29, 2013 # Updated: Feb 16, 2021 # Taken From: http://programmingnotes.org/ # File: uppercase.py # Description: Demonstrates checking if a char variable is uppercase # ============================================================================= def main(): # declare variables userInput = "" # this variable is a string letter = '' # this holds the individual character # get data from user userInput = input("Please enter an UPPERCASE letter: ") # get the 1st character in the string letter = userInput[0] # check to see if entered data falls between uppercase values if ((letter >= 'A') and (letter <= 'Z')): print("\n'%c' is an is an uppercase letter!" % (letter)) else: print("\nSorry, '%c' is not an uppercase letter.." % (letter)) if __name__ == "__main__": main() # http://programmingnotes.org/ |
Notice in line 21, an If statement was used, which checks to see if the user entered data falls between letter A and letter Z. We did that by using the “AND” operator. So that IF statement is basically saying (in plain english)
IF ('letter' is equal to or greater than 'A') AND ('letter' is equal to or less than 'Z')THEN it is an uppercase letter
The resulting code should give this as output
Please enter an UPPERCASE letter: g
Sorry, 'g' is not an uppercase letter..
==== CHECK IF LETTER IS A VOWEL ====
This example will utilize more if statements, checking to see if the user entered letter is a vowel or not. This will be very similar to the previous example, utilizing the OR operator once again.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# ============================================================================= # Author: Kenneth Perkins # Date: May 29, 2013 # Updated: Feb 16, 2021 # Taken From: http://programmingnotes.org/ # File: vowel.py # Description: Demonstrates checking if a char variable is a vowel # ============================================================================= def main(): # declare variables userInput = "" # this variable is a string letter = '' # this holds the individual character # get data from user userInput = input("Please enter a vowel: ") # get the 1st character in the string letter = userInput[0] # check to see if entered data is A,E,I,O,U,Y if ((letter == 'a')or(letter == 'A')or(letter == 'e')or (letter == 'E')or(letter == 'i')or(letter == 'I')or (letter == 'o')or(letter == 'O')or(letter == 'u')or (letter == 'U')or(letter == 'y')or(letter == 'Y')): print("\nCorrect, '%c' is a vowel!" % (letter)) else: print("\nSorry, '%c' is not a vowel.." % (letter)) if __name__ == "__main__": main() # http://programmingnotes.org/ |
This program should be very straight forward, and its basically checking to see if the user entered data is the letter A, E, I, O, U or Y.
The resulting code should give the following output
Please enter a vowel: K
Sorry, 'K' is not a vowel..
==== HELLO WORLD v2 ====
This last example will demonstrate using the string data type to print the line “Hello World!” to the screen.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# ============================================================================= # Author: Kenneth Perkins # Date: May 29, 2013 # Updated: Feb 16, 2021 # Taken From: http://programmingnotes.org/ # File: string.py # Description: Demonstrates using string variables # ============================================================================= def main(): # declare variables userInput = "" # this variable is a string # get data from user userInput = input("Please enter a sentence: ") # display string print("\nYou Entered: '%s'" % (userInput)) if __name__ == "__main__": main() # http://programmingnotes.org/ |
The following is similar to the other examples listed on this page, except we display the entire string instead of just simply the first character.
The resulting code should give following output
Please enter a sentence: Hello World!
You Entered: 'Hello World!'
C++ || Simple Spell Checker Using A Hash Table

The following is another programming assignment which was presented in a C++ Data Structures course. This assignment was used to gain more experience using hash tables.
REQUIRED KNOWLEDGE FOR THIS PROGRAM
Hash Table - What Is It?
How To Create A Spell Checker
How To Read Data From A File
Strtok - Split Strings Into Tokens
#include 'HashTable.h'
The Dictionary File - Download Here
== OVERVIEW ==
This program first reads words from a dictionary file, and inserts them into a hash table.
The dictionary file consists of a list of 62,454 correctly spelled lowercase words, separated by whitespace. The words are inserted into the hash table, with each bucket growing dynamically as necessary to hold all of the incoming data.
After the reading of the dictionary file is complete, the program prompts the user for input. After input is obtained, each word that the user enteres into the program is looked up within the hash table to see if it exists. If the user entered word exists within the hash table, then that word is spelled correctly. If not, a list of possible suggested spelling corrections is displayed to the screen.
== HASH TABLE STATISTICS ==
To better understand how hash tables work, this program reports the following statistics to the screen:
• The total size of the hash table.
• The size of the largest hash table bucket.
• The size of the smallest hash table bucket.
• The total number of buckets used.
• The average hash table bucket size.
A timer is used in this program to time (in seconds) how long it takes to read in the dictionary file. The program also saves each hash table bucket into a separate output .txt file. This is used to further visualize how the hash table data is internally being stored within memory.
== SPELL CHECKING ==
The easiest way to generate corrections for a spell checker is via a trial and error method. If we assume that the misspelled word contains only a single error, we can try all possible corrections and look each up in the dictionary.
Example:
wird: bird gird ward word wild wind wire wiry
Traditionally, spell checkers look for four possible errors: a wrong letter (“wird”), also knows as alteration. An inserted letter (“woprd”), a deleted letter (“wrd”), or a pair of adjacent transposed letters (“wrod”).
The easiest of which is checking for a wrong letter. For example, if a word isnt found in the dictionary, all variants of that word can be looked up by changing one letter. Given the user input “wird,” a one letter variant can be “aird”, “bird”, “cird”, etc. through “zird.” Then “ward”, “wbrd”, “wcrd” through “wzrd”, can be checked, and so forth. Whenever a match is found within the dictionary, the spelling correction should be displayed to the screen.
For a detailed analysis how the other methods can be constructed, click here.
===== SIMPLE SPELL CHECKER =====
This program uses a custom template.h class. To obtain the code for that class, click here.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 |
// ============================================================================ // Author: Kenneth Perkins // Date: Jan 31, 2013 // Taken From: http://programmingnotes.org/ // File: SpellCheck.cpp // Description: This is a simple spell checker which tests the HashTable.h // class. // ============================================================================ #include <iostream> #include <fstream> #include <cctype> #include <cstring> #include <string> #include <iomanip> #include <ctime> #include <limits> #include "HashTable.h" using namespace std; // iterator declaration for hash table typedef HashTable<string>::Iterator iterDec; // hash table size const int TABLE_SIZE = 19000; // strtok delimiters const char* DELIMITERS = " ,.-\':;?()+*/\\%$#!\"@\^&"; // function prototypes void PrintTableStats(HashTable<string>& hashTable); int SpellCheck(HashTable<string>& hashTable, string word); string ToLowerCase(string word); int main() { // declare variables int result = 0; string userInput; string currWord; clock_t beg; // used to time the hashtable load clock_t end; // used to time the hashtable load char response; ifstream infile; HashTable<string> hashTable(TABLE_SIZE); // open the dictionary file infile.open("INPUT_Dictionary_programmingnotes_freeweq_com.txt"); // check if the file exists, EXIT if it doesnt if(infile.fail()) { cout<<"\n\n**ERROR - The dictionary file could not be found...\n"; exit(1); } cerr<<"\nLoading dictionary...."; beg = clock(); // start the timer // get data from file and put into hashtable while(infile >> currWord) { // makes sure duplicate words arent inserted into table if(!hashTable.Count(currWord)) { hashTable.Insert(currWord); } } infile.close(); PrintTableStats(hashTable); end = clock()-beg; // end the timer cout<<"\n\nDictionary loaded in "<< (double)end / ((double)CLOCKS_PER_SEC)<<" secs!"; // creates a line separator cout<<endl; cout.fill('-'); cout<<left<<setw(50)<<""<<endl; do{ // get user input cout<<"\n>> Please enter a sentence: "; getline(cin,userInput); cout<<endl; // split each word from the string into individual words to check if // they are spelled correctly char* splitInput = strtok(const_cast<char*>(userInput.c_str()),DELIMITERS); while(splitInput!=NULL) { currWord = splitInput; currWord = ToLowerCase(currWord); result += SpellCheck(hashTable,currWord); splitInput = strtok(NULL,DELIMITERS); } // display results if(result > 0) { cout<<"Number of words spelled incorrectly: "<<result<<endl; result = 0; } // ask for more data cout<<"\nDo you want to enter another sentence? (y/n): "; cin >> response; cin.ignore(numeric_limits<streamsize>::max(),'\n'); // clear the cin buffer }while(toupper(response)=='Y'); cout<<"\nBYE!!\n"; return 0; }// end of main void PrintTableStats(HashTable<string>& hashTable) { int largestBucket = -9999999; int largestIndex = 0; int smallestBucket = 9999999; int smallestIndex = 0; double numBuckestUsed = 0; ofstream outfile("OUTPUT_HashTable_Stats_programmingnotes_freeweq_com.txt"); for(int x=0; x < hashTable.TableSize(); ++x) { // iterator is used to traverse each hashtable bucket iterDec it = hashTable.begin(x); if(!hashTable.IsEmpty(x)) { if(smallestBucket > hashTable.BucketSize(x)) { smallestBucket = hashTable.BucketSize(x); smallestIndex = x; } if(largestBucket < hashTable.BucketSize(x)) { largestBucket = hashTable.BucketSize(x); largestIndex = x; } ++numBuckestUsed; outfile<<"\nBucket #"<<x<<":\n"; for(int y = 0; y < hashTable.BucketSize(x); ++y) { outfile <<"\t"<< it[y] << endl; } } } cout<<"Complete!\n"; // creates a line separator cout<<endl; cout.fill('-'); cout<<left<<setw(50)<<""<<endl; cout<<"Total dictionary words = "<<hashTable.TotalElems()<<endl <<"Hash table size = "<<hashTable.TableSize()<<endl <<"Largest bucket size = "<<largestBucket<< " items at index #"<<largestIndex<<endl <<"Smallest bucket size = "<<smallestBucket<< " items at index #"<<smallestIndex<<endl <<"Total buckets used = "<<numBuckestUsed<<endl <<"Total percent of hash table used = "<<(numBuckestUsed/hashTable.TableSize())*100<<"%"<<endl <<"Average bucket size = "<<(hashTable.TotalElems()/numBuckestUsed)<<" items"; }// end of PrintTableStats int SpellCheck(HashTable<string>& hashTable, string word) { int result = 0; int suggestion = 0; string remove[256]; int numRemove=0; if(!hashTable.Count(word)) { ++result; cout<<"** "<<word<<": "; // alteration & insertion for(unsigned x = 0; x < word.length(); ++x) { string alteration = word; for(char c = 'a'; c <= 'z'; ++c) { //alteration alteration[x] = c; if(hashTable.Count(alteration)) { cout<<alteration<<", "; remove[numRemove++] = alteration; ++suggestion; // remove the entry so it isnt displayed multiple times hashTable.Remove(alteration); } //insertion string insertion = word.substr(0, x) + c + word.substr(x); if(hashTable.Count(insertion)) { cout<<insertion<<", "; remove[numRemove++] = insertion; ++suggestion; // remove the entry so it isnt displayed multiple times hashTable.Remove(insertion); } } } // transposition & deletion for(unsigned x = 0; x < word.length()-1;++x) { // transposition string transposition = word.substr(0,x) + word[x+1] + word[x] + word.substr(x+2); if(hashTable.Count(transposition)) { cout<<transposition<<", "; remove[numRemove++] = transposition; ++suggestion; // remove the entry so it isnt displayed multiple times hashTable.Remove(transposition); } // deletion string deletion = word.substr(0, x)+ word.substr(x + 1); if(hashTable.Count(deletion)) { cout<<deletion<<", "; remove[numRemove++] = deletion; ++suggestion; // remove the entry so it isnt displayed multiple times hashTable.Remove(deletion); } } // place the removed items back inside the hash table while(numRemove>=0) { hashTable.Insert(remove[numRemove--]); } if(suggestion < 1) { cout<<"No spelling suggestion found..."; } cout<<endl<<endl; } return result; }// end of SpellCheck string ToLowerCase(string word) { for(unsigned x = 0; x < word.length(); ++x) { word[x] = tolower(word[x]); } return word; }// http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
Remember to include the data file.
Once compiled, you should get this as your output
Loading dictionary....Complete!--------------------------------------------------
Total dictionary words = 61286
Hash table size = 19000
Largest bucket size = 13 items at index #1551
Smallest bucket size = 1 items at index #11
Total buckets used = 18217
Total percent of hash table used = 95.8789%
Average bucket size = 3.36422 itemsDictionary loaded in 1.861 secs!
-------------------------------------------------->> Please enter a sentence: wird
** wird: bird, gird, ward, weird, word, wild, wind, wire, wired, wiry,
Number of words spelled incorrectly: 1
Do you want to enter another sentence? (y/n): y
--------------------------------------------------
>> Please enter a sentence: woprd
** woprd: word,
Number of words spelled incorrectly: 1
Do you want to enter another sentence? (y/n): y
--------------------------------------------------
>> Please enter a sentence: wrd
** wrd: ard, ord, ward, wed, word,
Number of words spelled incorrectly: 1
Do you want to enter another sentence? (y/n): y
--------------------------------------------------
>> Please enter a sentence: wrod
** wrod: brod, trod, wood, rod, word,
Number of words spelled incorrectly: 1
Do you want to enter another sentence? (y/n): y
--------------------------------------------------
>> Please enter a sentence: New! Safe and efective
** efective: defective, effective, elective,
Number of words spelled incorrectly: 1
Do you want to enter another sentence? (y/n): y
--------------------------------------------------
>> Please enter a sentence: This is a sentance with no corections gygyuigigigiug
** sentance: sentence,
** corections: corrections,
** gygyuigigigiug: No spelling suggestion found...
Number of words spelled incorrectly: 3
Do you want to enter another sentence? (y/n): n
BYE!!
C++ || Custom Template Hash Table With Iterator Using Separate Chaining
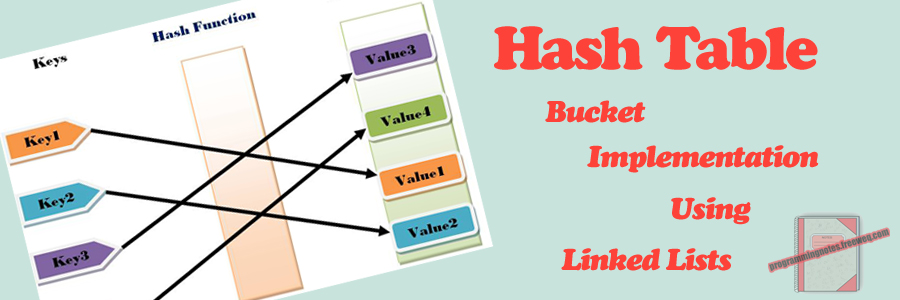
Looking for sample code for a Hash Map? Click here!
Before we get into the code, what is a Hash Table? Simply put, a Hash Table is a data structure used to implement an associative array; one that can map unique “keys” to specific values. While a standard array requires that indice subscripts be integers, a hash table can use a floating point value, a string, another array, or even a structure as the index. That index is called the “key,” and the contents within the array at that specific index location is called the value. A hash table uses a hash function to generate an index into the table, creating buckets or slots, from which the correct value can be found.
To illustrate, compare a standard array full of data (100 elements). If the position was known for the specific item that we wanted to access within the array, we could quickly access it. For example, if we wanted to access the data located at index #5 in the array, we could access it by doing:
array[5]; // do something with the data
Here, we dont have to search through each element in the array to find what we need, we just access it at index #5. The question is, how do we know that index #5 stores the data that we are looking for? If we have a large set of data, doing a sequential search over each item within the array can be very inefficient. That is where hashing comes in handy. Given a “key,” we can apply a hash function to a unique index or bucket to find the data that we wish to access.
So in essence, a hash table is a data structure that stores key/value pairs, and is typically used because they are ideal for doing a quick search of items.
Though hashing is ideal, it isnt perfect. It is possible for multiple items to be hashed into the same location. Hash “collisions” are practically unavoidable when hashing large data sets. The code demonstrated on this page handles collisions via separate chaining, utilizing an array of linked list head nodes to store multiple values within one bucket – should any collisions occur.
An iterator was also implemented, making data access that much more simple within the hash table class. Click here for an overview demonstrating how custom iterators can be built.
Looking for sample code for a Hash Map? Click here!
=== CUSTOM TEMPLATE HASH TABLE WITH ITERATOR ===
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 |
// ============================================================================ // Author: Kenneth Perkins // Date: Jan 18, 2013 // Taken From: http://programmingnotes.org/ // File: HashTable.h // Description: This is a class which implements various functions which // demonstrates the use of a Hash Table. // ============================================================================ #ifndef TEMPLATE_HASH_TABLE #define TEMPLATE_HASH_TABLE #include <iostream> #include <string> #include <sstream> #include <cstdlib> // if user doesnt define, this is the // default hash table size const int HASH_SIZE = 100; template <class ItemType> class HashTable { public: HashTable(int hashSze = HASH_SIZE); /* Function: Constructor initializes hash table Precondition: None Postcondition: Defines private variables */ bool IsEmpty(int key); /* Function: Determines whether hash table is empty at the given key Precondition: Hash table has been created Postcondition: The function = true if the hash table is empty and the function = false if hash table is not empty */ bool IsFull(); /* Function: Determines whether hash table is full Precondition: Hash table has been created Postcondition: The function = true if the hash table is full and the function = false if hash table is not full */ int Hash(ItemType newItem); /* Function: Computes and returns a unique hash key for a given item The returned key is the given cell where the item resides Precondition: Hash table has been created and is not full Postcondition: The hash key is returned */ void Insert(ItemType newItem); /* Function: Adds newItem to the back of the list at a given key in the hash table A unique hash key is automatically generated for each newItem Precondition: Hash table has been created and is not full Postcondition: Item is in the hash table */ void Append(int key, ItemType newItem); /* Function: Adds new item to the end of the list at a given key in the hash table Precondition: Hash table has been created and is not full Postcondition: Item is in the hash table */ bool Remove(ItemType deleteItem, int key = -1); /* Function: Removes the first instance from the table whose value is "deleteItem" Optional second parameter indicates the key where deleteItem is located Precondition: Hash table has been created and is not empty Postcondition: The function = true if deleteItem is found and the function = false if deleteItem is not found */ void Sort(int key); /* Function: Sort the items in the table at the given key Precondition: Hash table has been initialized Postcondition: The hash table is sorted */ int TableSize(); /* Function: Return the size of the hash table Precondition: Hash table has been initialized Postcondition: The size of the hash table is returned */ int TotalElems(); /* Function: Return the total number of elements contained in the hash table Precondition: Hash table has been initialized Postcondition: The size of the hash table is returned */ int BucketSize(int key); /* Function: Return the number of items contained in the hash table cell at the given key Precondition: Hash table has been initialized Postcondition: The size of the given key cell is returned */ int Count(ItemType searchItem); /* Function: Return the number of times searchItem appears in the table. Only works on items located in their correctly hashed cells Precondition: Hash table has been initialized Postcondition: The number of times searchItem appears in the table is returned */ void MakeEmpty(); /* Function: Initializes hash table to an empty state Precondition: Hash table has been created Postcondition: Hash table no longer exists */ ~HashTable(); /* Function: Removes the hash table Precondition: Hash table has been declared Postcondition: Hash table no longer exists */ // -- ITERATOR CLASS -- class Iterator; /* Function: Class declaration to the iterator Precondition: Hash table has been declared Postcondition: Hash Iterator has been declared */ Iterator begin(int key){return(!IsEmpty(key)) ? head[key]:NULL;} /* Function: Returns the beginning of the current hash cell list Precondition: Hash table has been declared Postcondition: Hash cell has been returned to the Iterator */ Iterator end(int key=0){return NULL;} /* Function: Returns the end of the current hash cell list Precondition: Hash table has been declared Postcondition: Hash cell has been returned to the Iterator */ private: struct node { ItemType currentItem; node* next; }; node** head; // array of linked list declaration - front of each hash table cell int hashSize; // the size of the hash table (how many cells it has) int totElems; // holds the total number of elements in the entire table int* bucketSize; // holds the total number of elems in each specific hash table cell }; //========================= Implementation ================================// template<class ItemType> HashTable<ItemType>::HashTable(int hashSze) { hashSize = hashSze; head = new node*[hashSize]; bucketSize = new int[hashSize]; for(int x=0; x < hashSize; ++x) { head[x] = NULL; bucketSize[x] = 0; } totElems = 0; }/* End of HashTable */ template<class ItemType> bool HashTable<ItemType>::IsEmpty(int key) { if(key >=0 && key < hashSize) { return head[key] == NULL; } return true; }/* End of IsEmpty */ template<class ItemType> bool HashTable<ItemType>::IsFull() { try { node* location = new node; delete location; return false; } catch(std::bad_alloc&) { return true; } }/* End of IsFull */ template<class ItemType> int HashTable<ItemType>::Hash(ItemType newItem) { long h = 19937; std::stringstream convert; // convert the parameter to a string using "stringstream" which is done // so we can hash multiple datatypes using only one function convert << newItem; std::string temp = convert.str(); for(unsigned x=0; x < temp.length(); ++x) { h = (h << 6) ^ (h >> 26) ^ temp[x]; } return abs(h % hashSize); } /* End of Hash */ template<class ItemType> void HashTable<ItemType>::Insert(ItemType newItem) { if(IsFull()) { //std::cout<<"nINSERT ERROR - HASH TABLE FULLn"; } else { int key = Hash(newItem); Append(key,newItem); } }/* End of Insert */ template<class ItemType> void HashTable<ItemType>::Append(int key, ItemType newItem) { if(IsFull()) { //std::cout<<"nAPPEND ERROR - HASH TABLE FULLn"; } else { node* newNode = new node; // adds new node newNode-> currentItem = newItem; newNode-> next = NULL; if(IsEmpty(key)) { head[key] = newNode; } else { node* tempPtr = head[key]; while(tempPtr-> next != NULL) { tempPtr = tempPtr-> next; } tempPtr-> next = newNode; } ++bucketSize[key]; ++totElems; } }/* End of Append */ template<class ItemType> bool HashTable<ItemType>::Remove(ItemType deleteItem, int key) { bool isFound = false; node* tempPtr; if(key == -1) { key = Hash(deleteItem); } if(IsEmpty(key)) { //std::cout<<"nREMOVE ERROR - HASH TABLE EMPTYn"; } else if(head[key]->currentItem == deleteItem) { tempPtr = head[key]; head[key] = head[key]-> next; delete tempPtr; --totElems; --bucketSize[key]; isFound = true; } else { for(tempPtr = head[key];tempPtr->next!=NULL;tempPtr=tempPtr->next) { if(tempPtr->next->currentItem == deleteItem) { node* deleteNode = tempPtr->next; tempPtr-> next = tempPtr-> next-> next; delete deleteNode; isFound = true; --totElems; --bucketSize[key]; break; } } } return isFound; }/* End of Remove */ template<class ItemType> void HashTable<ItemType>::Sort(int key) { if(IsEmpty(key)) { //std::cout<<"nSORT ERROR - HASH TABLE EMPTYn"; } else { int listSize = BucketSize(key); bool sorted = false; do{ sorted = true; int x = 0; for(node* tempPtr = head[key]; tempPtr->next!=NULL && x < listSize-1; tempPtr=tempPtr->next,++x) { if(tempPtr-> currentItem > tempPtr->next->currentItem) { ItemType temp = tempPtr-> currentItem; tempPtr-> currentItem = tempPtr->next->currentItem; tempPtr->next->currentItem = temp; sorted = false; } } --listSize; }while(!sorted); } }/* End of Sort */ template<class ItemType> int HashTable<ItemType>::TableSize() { return hashSize; }/* End of TableSize */ template<class ItemType> int HashTable<ItemType>::TotalElems() { return totElems; }/* End of TotalElems */ template<class ItemType> int HashTable<ItemType>::BucketSize(int key) { return(!IsEmpty(key)) ? bucketSize[key]:0; }/* End of BucketSize */ template<class ItemType> int HashTable<ItemType>::Count(ItemType searchItem) { int key = Hash(searchItem); int search = 0; if(IsEmpty(key)) { //std::cout<<"nCOUNT ERROR - HASH TABLE EMPTYn"; } else { for(node* tempPtr = head[key];tempPtr!=NULL;tempPtr=tempPtr->next) { if(tempPtr->currentItem == searchItem) { ++search; } } } return search; }/* End of Count */ template<class ItemType> void HashTable<ItemType>::MakeEmpty() { totElems = 0; for(int x=0; x < hashSize; ++x) { if(!IsEmpty(x)) { //std::cout << "Destroying nodes ...n"; while(!IsEmpty(x)) { node* temp = head[x]; //std::cout << temp-> currentItem <<std::endl; head[x] = head[x]-> next; delete temp; } } bucketSize[x] = 0; } }/* End of MakeEmpty */ template<class ItemType> HashTable<ItemType>::~HashTable() { MakeEmpty(); delete[] head; delete[] bucketSize; }/* End of ~HashTable */ // END OF THE HASH TABLE CLASS // ----------------------------------------------------------- // START OF THE HASH TABLE ITERATOR CLASS template <class ItemType> class HashTable<ItemType>::Iterator : public std::iterator<std::forward_iterator_tag,ItemType>, public HashTable<ItemType> { public: // Iterator constructor Iterator(node* otherIter = NULL) { itHead = otherIter; } ~Iterator() {} // The assignment and relational operators are straightforward Iterator& operator=(const Iterator& other) { itHead = other.itHead; return(*this); } bool operator==(const Iterator& other)const { return itHead == other.itHead; } bool operator!=(const Iterator& other)const { return itHead != other.itHead; } bool operator<(const Iterator& other)const { return itHead < other.itHead; } bool operator>(const Iterator& other)const { return other.itHead < itHead; } bool operator<=(const Iterator& other)const { return (!(other.itHead < itHead)); } bool operator>=(const Iterator& other)const { return (!(itHead < other.itHead)); } // Update my state such that I refer to the next element in the // HashTable. Iterator operator+(int incr) { node* temp = itHead; for(int x=0; x < incr && temp!= NULL; ++x) { temp = temp->next; } return temp; } Iterator operator+=(int incr) { for(int x=0; x < incr && itHead!= NULL; ++x) { itHead = itHead->next; } return itHead; } Iterator& operator++() // pre increment { if(itHead != NULL) { itHead = itHead->next; } return(*this); } Iterator operator++(int) // post increment { node* temp = itHead; this->operator++(); return temp; } ItemType& operator[](int incr) { // Return "junk" data // to prevent the program from crashing if(itHead == NULL || (*this + incr) == NULL) { return junk; } return(*(*this + incr)); } // Return a reference to the value in the node. I do this instead // of returning by value so a caller can update the value in the // node directly. ItemType& operator*() { // Return "junk" data // to prevent the program from crashing if(itHead == NULL) { return junk; } return itHead->currentItem; } ItemType* operator->() { return(&**this); } private: node* itHead; ItemType junk; }; #endif // http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The iterator class starts on line #368, and is built to support most of the standard relational operators, as well as arithmetic operators such as ‘+,+=,++’ (pre/post increment). The * (star), bracket [] and -> arrow operators are also supported. Click here for an overview demonstrating how custom iterators can be built.
The rest of the code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
Looking for sample code for a Hash Map? Click here!
===== DEMONSTRATION HOW TO USE =====
Use of the above template class is the same as many of its STL template class counterparts. Here are sample programs demonstrating its use.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
// DEMONSTRATE USE OF THE REMOVE AND SORT FUNCTIONS #include <iostream> #include <ctime> #include <string> #include <cstdlib> #include <iomanip> #include "HashTable.h" using namespace std; // iterator declarations typedef HashTable<string>::Iterator strIterDec; // hash table size const int TABLE_SIZE = 5; int main() { // delcare variables srand(time(NULL)); const string names[]={"Alva","Edda","Hiram","Lemuel","Della","Roseann","Sang", "Evelia","Claire","Marylou","Magda","Irvin","Reagan","Deb","Hillary", "Tuyetm","Cherilyn","Amina","Justin","Neville","Jessica","Demi", "Graham","Cinderella","Freddy","Vivan","Marjorie","Krystal","Liza", "Spencer","Jordon","Bernie","Geraldine","Kati","Jetta","Carmella", "Chery","Earlene","Gene","Lorri","Albertina","Ula","Karena","Johanna", "Alex","Tobias","Lashawna","Domitila","Chantel","Deneen","Nigel", "Lashanda","Donn","Theda","Many","Jeramy","Jodee","Tamra","Dessie", "Lawrence","Jaime","Basil","Roger","Cythia","Homer","Lilliam","Victoria", "Tod","Harley","Meghann","Jacquelyne","Arie","Rosemarie","Lyndon","Blanch", "Kenneth","Perkins","Kaleena"}; int nameLen = sizeof(names)/sizeof(names[0]); // Hash table class declarations HashTable<string> strHash(TABLE_SIZE); // insert 10 items into each hash table for(int x=0; x < (TABLE_SIZE*2); ++x) { // place all data in bucket 0 // NOTE: you dont want to place all data into one // bucket, this is done for demo purposes only // Normally use the "Insert" function instead strHash.Append(0,names[rand()%(nameLen-1)]); } // assign the iterator to bucket 0 strIterDec it = strHash.begin(0); // display bucket size cout<<"Bucket #0 has "<<strHash.BucketSize(0)<<" items"<<endl; // display the first item cout<<"The first element in bucket #0 is "<< it[0] <<endl; // remove the first item in bucket 0 // NOTE: the second parameter is optional // but since we know we want bucket 0, we use it here strHash.Remove(it[0],0); // update the iterator to the new table state it = strHash.begin(0); // display the new first item cout<<"nNow bucket #0 has "<<strHash.BucketSize(0)<<" items"<<endl; cout<<"The first element in bucket #0 is "<< it[0] <<endl; // display all the items within the "strHash" table cout<<"nThe unsorted items in strHash bucket #0:n"; for(int x=0; x < strHash.BucketSize(0); ++x) { cout << "it[] = " << it[x] << endl; } // sort the items in bucket 0 strHash.Sort(0); // display all the items within the "strHash" table cout<<"nThe sorted items in strHash bucket #0:n"; for(int x=0; x < strHash.BucketSize(0); ++x) { cout << "it[] = " << it[x] << endl; } return 0; }// http://programmingnotes.org/ |
SAMPLE OUTPUT:
Bucket #0 has 10 items
The first element in bucket #0 is HomerNow bucket #0 has 9 items
The first element in bucket #0 is TamraThe unsorted items in strHash bucket #0:
it[] = Tamra
it[] = Lyndon
it[] = Johanna
it[] = Perkins
it[] = Alva
it[] = Jordon
it[] = Neville
it[] = Lawrence
it[] = JettaThe sorted items in strHash bucket #0:
it[] = Alva
it[] = Jetta
it[] = Johanna
it[] = Jordon
it[] = Lawrence
it[] = Lyndon
it[] = Neville
it[] = Perkins
it[] = Tamra
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 |
// DISPLAY ALL DATA INSIDE TABLE USING STD::STRING / INT / STRUCT #include <iostream> #include <ctime> #include <string> #include <cstdlib> #include <iomanip> #include "HashTable.h" using namespace std; // sample struct demo struct MyStruct { string name; }; // iterator declarations typedef HashTable<string>::Iterator strIterDec; typedef HashTable<int>::Iterator intIterDec; typedef HashTable<MyStruct>::Iterator strctIterDec; // hash table size const int TABLE_SIZE = 10; int main() { // delcare variables srand(time(NULL)); const string names[]={"Alva","Edda","Hiram","Lemuel","Della","Roseann","Sang", "Evelia","Claire","Marylou","Magda","Irvin","Reagan","Deb","Hillary", "Tuyetm","Cherilyn","Amina","Justin","Neville","Jessica","Demi", "Graham","Cinderella","Freddy","Vivan","Marjorie","Krystal","Liza", "Spencer","Jordon","Bernie","Geraldine","Kati","Jetta","Carmella", "Chery","Earlene","Gene","Lorri","Albertina","Ula","Karena","Johanna", "Alex","Tobias","Lashawna","Domitila","Chantel","Deneen","Nigel", "Lashanda","Donn","Theda","Many","Jeramy","Jodee","Tamra","Dessie", "Lawrence","Jaime","Basil","Roger","Cythia","Homer","Lilliam","Victoria", "Tod","Harley","Meghann","Jacquelyne","Arie","Rosemarie","Lyndon","Blanch", "Kenneth","Perkins","Kaleena"}; int nameLen = sizeof(names)/sizeof(names[0]); // Hash table class declarations HashTable<string> strHash(TABLE_SIZE); HashTable<int> intHash = TABLE_SIZE; HashTable<MyStruct> strctHash = TABLE_SIZE; // access struct element MyStruct strctAccess; // insert 20 items into each hash table for(int x=0; x < (TABLE_SIZE*2); ++x) { // Use the "insert" function to place data into the hash table // this function automatically hashes the basic datatypes // i.e: int, double, char, char*, string strHash.Insert(names[rand()%(nameLen-1)]); intHash.Insert(rand()%10000); // The "insert" function cant be used on a struct, so we // use the "append" function for the struct declaration. // We use the "strHash" class declaration to use its // hash function, then place the struct in an appropriate // hashed bucket strctAccess.name = names[rand()%(nameLen-1)]; int strctHashKey = strHash.Hash(strctAccess.name); strctHash.Append(strctHashKey,strctAccess); } // display all the items within the "strHash" table for(int x=0; x < strHash.TableSize(); ++x) { if(!strHash.IsEmpty(x)) { cout<<"nstrHash Bucket #"<<x<<":n"; for(strIterDec it = strHash.begin(x); it != strHash.end(x); it+=1) { // access elements using the * (star) operator cout << "*it = " << *it << endl; } } } // creates a line seperator cout<<endl; cout.fill('-'); cout<<left<<setw(80)<<""<<endl; // display all the items within the "intHash" table for(int x=0; x < intHash.TableSize(); ++x) { intIterDec it = intHash.begin(x); if(!intHash.IsEmpty(x)) { cout<<"nintHash Bucket #"<<x<<":n"; for(int y = 0; y < intHash.BucketSize(x); ++y) { // access elements using the [] operator cout << "it[] = " << it[y] << endl; } } } // creates a line seperator cout<<endl; cout.fill('-'); cout<<left<<setw(80)<<""<<endl; // display all the items within the "strctHash" table for(int x=0; x < strctHash.TableSize(); ++x) { if(!strctHash.IsEmpty(x)) { cout<<"nstrctHash Bucket #"<<x<<":n"; for(strctIterDec it = strctHash.begin(x); it!=strctHash.end(x); it=it+1) { // access struct/class elements using the -> operator cout << "it-> = " << it->name << endl; } } } return 0; }// http://programmingnotes.org/ |
SAMPLE OUTPUT:
strHash Bucket #0:
*it = Cinderella
*it = Perkins
*it = Krystal
*it = Roger
*it = RogerstrHash Bucket #1:
*it = Lilliam
*it = Lilliam
*it = ThedastrHash Bucket #2:
*it = AriestrHash Bucket #3:
*it = MagdastrHash Bucket #6:
*it = Edda
*it = Irvin
*it = Kati
*it = LyndonstrHash Bucket #7:
*it = Deb
*it = JaimestrHash Bucket #8:
*it = Neville
*it = VictoriastrHash Bucket #9:
*it = Chery
*it = Evelia--------------------------------------------
intHash Bucket #0:
it[] = 2449
it[] = 6135intHash Bucket #1:
it[] = 1120
it[] = 852intHash Bucket #2:
it[] = 5727intHash Bucket #3:
it[] = 1174intHash Bucket #4:
it[] = 2775
it[] = 3525
it[] = 8375intHash Bucket #5:
it[] = 4322
it[] = 8722
it[] = 5016intHash Bucket #6:
it[] = 5053
it[] = 7231
it[] = 1571intHash Bucket #7:
it[] = 1666
it[] = 4510
it[] = 1548
it[] = 3646intHash Bucket #9:
it[] = 2756--------------------------------------------
strctHash Bucket #0:
it-> = Cherilyn
it-> = RogerstrctHash Bucket #1:
it-> = Tamra
it-> = Alex
it-> = ThedastrctHash Bucket #2:
it-> = Nigel
it-> = Alva
it-> = AriestrctHash Bucket #4:
it-> = BasilstrctHash Bucket #5:
it-> = TodstrctHash Bucket #6:
it-> = Irvin
it-> = LyndonstrctHash Bucket #7:
it-> = Amina
it-> = Hillary
it-> = Kenneth
it-> = AminastrctHash Bucket #8:
it-> = Gene
it-> = Lemuel
it-> = GenestrctHash Bucket #9:
it-> = Albertina
Java || Snippet – How To Find The Highest & Lowest Numbers Contained In An Integer Array
This page will consist of a simple demonstration for finding the highest and lowest numbers contained in an integer array.
REQUIRED KNOWLEDGE FOR THIS SNIPPET
Finding the highest/lowest values in an array can be found in one or two ways. The first way would be via a sort, which would obviously render the highest/lowest numbers contained in the array because the values would be sorted in order from highest to lowest. But a sort may not always be practical, especially when you want to keep the array values in the same order that they originally came in.
The second method of finding the highest/lowest values is by traversing through the array, literally checking each value it contains one by one to determine if the current number which is being compared truly is a target value or not. That method will be displayed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
import java.util.Random; public class HighestLowestArray { // global variable declaration final static int ARRAY_SIZE = 14; // const int allocating space for the array static Random rand = new Random(); // this is the call to the "Random" class public static void main(String[] args) { // declare & initialize variables int[] arry = new int[ARRAY_SIZE]; int highestScore = -999999; int lowestScore = 999999; System.out.println("Welcome to My Programming Notes' Java Program.n"); // place random numbers into the array for(int x = 0; x < ARRAY_SIZE; ++x) { arry[x] = rand.nextInt(100)+1; } System.out.println("Original array values:"); // Output the original array values for(int x = 0; x < ARRAY_SIZE; ++x) { System.out.print(arry[x]+" "); } System.out.println(""); // creates a line seperator setwLF("",60,'-'); // use a for loop to go thru the array checking to see the highest/lowest element System.out.print("nThese are the highest and lowest array values: "); for(int index=0; index < ARRAY_SIZE; ++index) { // if current score in the array is bigger than the current 'highestScore' // element, then set 'highestScore' equal to the current array element if(arry[index] > highestScore) { highestScore = arry[index]; } // if current 'lowestScore' element is bigger than the current array element, // then set 'lowestScore' equal to the current array element if(arry[index] < lowestScore) { lowestScore = arry[index]; } }// end for loop // display the results to the user System.out.print("nHighest: "+highestScore); System.out.print("nLowest: "+lowestScore); System.out.println(""); }// end of main static public void setwLF(String str, int width, char fill) { for (int x = str.length(); x < width; ++x) { System.out.print(fill); } System.out.print(str); }// end of setwLF }// http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
Once compiled, you should get this as your output
Welcome to My Programming Notes' Java Program.Original array values:
36 35 46 86 86 58 44 38 79 52 27 78 65 79
------------------------------------------------------------
These are the highest and lowest array values:
Highest: 86
Lowest: 27
Java || Modulus – Celsius To Fahrenheit Conversion Displaying Degrees Divisible By 10 Using Modulus

This page will consist of two simple programs which demonstrate the use of the modulus operator (%).
REQUIRED KNOWLEDGE FOR THIS PROGRAM
Modulus
Do/While Loop
Methods (A.K.A "Functions") - What Are They?
Simple Math - Divisibility
Celsius to Fahrenheit Conversion
===== FINDING THE DIVISIBILITY OF A NUMBER =====
Take a simple arithmetic problem: what’s left over when you divide an odd number by an even number? The answer may not be easy to compute, but we know that it will most likely result in an answer which has a decimal remainder. How would we determine the divisibility of a number in a programming language like Java? That’s where the modulus operator comes in handy.
To have divisibility means that when you divide the first number by another number, the quotient (answer) is a whole number (i.e – no decimal values). Unlike the division operator, the modulus operator (‘%’), has the ability to give us the remainder of a given mathematical operation that results from performing integer division.
To illustrate this, here is a simple program which prompts the user to enter a number. Once the user enters a number, they are asked to enter in a divisor for the previous number. Using modulus, the program will determine if the second number is divisible by the first number. If the modulus result returns 0, the two numbers are divisible. If the modulus result does not return 0, the two numbers are not divisible. The program will keep re-prompting the user to enter in a correct choice until a correct result is obtained.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
import java.util.Scanner; public class Modulus { // global variable declaration static Scanner cin = new Scanner(System.in); public static void main(String[] args) { // declare & initialize variables int numerator = 0; int denominator = 0; double multiple = 0; System.out.println("Welcome to My Programming Notes' Java Program.n"); // get first number System.out.print("Please enter a value: "); numerator = cin.nextInt(); // get second number System.out.print("nPlease enter a factor of "+numerator+": "); do{ // loop will keep going until the user enters a correct answer denominator = cin.nextInt(); // this is the modulus declaration, which will find the // remainder between the 2 numbers multiple = numerator % denominator; // if the modulus result returns 0, the 2 numbers // are divisible if(multiple == 0) { System.out.println("nCorrect! "+numerator+" is divisible by " +denominator); System.out.println("n("+numerator+"/"+denominator+") = " + ""+(numerator/denominator)); } // if the user entered an incorrect choice, promt an error message else { System.out.print("nIncorrect, "+numerator+" is not divisible by " +denominator); System.out.print(".nnPlease enter a new multiple integer for " +numerator+": "); } }while(multiple != 0); // ^ loop stops once user enters correct choice }// end of main }// http://programmingnotes.org/ |
The above program determines if number ‘A’ is divisible be number ‘B’ via modulus. Unlike the division operator, which does not return the remainder of a number, the modulus operator does, thus we are able to find divisibility between two numbers.
To demonstrate the above code, here is a sample run:
Welcome to My Programming Notes' Java Program.Please enter a value: 21
Please enter a factor of 21: 5Incorrect, 21 is not divisible by 5.
Please enter a new multiple integer for 21: 7
Correct! 21 is divisible by 7(21/7) = 3
===== CELSIUS TO FAHRENHEIT CONVERSION DISPLAYING DEGREES DIVISIBLE BY 10 =====
Now that we understand how modulus works, the second program shouldn’t be too difficult. This function first prompts the user to enter in an initial (low) value. After the program obtains the low value from the user, the program will ask for another (high) value. After it obtains the needed information, it displays all the degrees, from the range of the low number to the high number, which are divisible by 10. So if the user enters a low value of 3 and a high value of 303, the program will display all of the Celsius to Fahrenheit degrees within that range which are divisible by 10.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
import java.util.Scanner; public class Temperature { // global variable declaration static Scanner cin = new Scanner(System.in); public static void main(String[] args) { // declare & initialize variables int low = 0; int high = 0; double degreeFahrenhiet = 0; double multiple = 0; System.out.println("Welcome to My Programming Notes' Java Program.n"); // get data from user System.out.print("Enter a low number: "); low = cin.nextInt(); System.out.print("nEnter a high number: "); high = cin.nextInt(); // displays data back to user in table form System.out.print("nCelsius Fahrenheit:n"); // display the initial 'low' converted degrees to the user System.out.println(low+"t"+ConvertCelsiusToFahrenheit(low)); // this loop displays all the degrees that are divisible by 10 do{ // this increments the current degree number by 1 ++low; // this converts the current number from celsius to fahrenhiet degreeFahrenhiet = ConvertCelsiusToFahrenheit(low); // this is the modulus operation which finds the // numbers which are divisible by 10 multiple = low % 10; // the program will only display the degrees to the user via // cout which are divisible by 10 if(multiple == 0) { System.out.println(low+"t"+degreeFahrenhiet); } }while(low < high); // ^ loop stops once the 'low' variable reaches the 'high' variable // displays the 'high' converted degrees to the user System.out.println(high+"t"+ConvertCelsiusToFahrenheit(high)); }// end of main static double ConvertCelsiusToFahrenheit(int degree) { return ((1.8 * degree) + 32.0); }// end of ConvertCelsiusToFahrenheit }// http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
Once compiled, you should get this as your output
Welcome to My Programming Notes' Java Program.Enter a low number: 3
Enter a high number: 303Celsius Fahrenheit:
3..........37.4
10.........50
20.........68
30.........86
40........104
50........122
60........140
70........158
80........176
90........194
100.......212
110.......230
120.......248
130.......266
140.......284
150.......302
160.......320
170.......338
180.......356
190.......374
200.......392
210.......410
220.......428
230.......446
240.......464
250.......482
260.......500
270.......518
280.......536
290.......554
300.......572
303.......577.4
Java || Random Number Guessing Game Using Random & Do/While Loop

This is a simple guessing game, which demonstrates the use of the “Random” class to generate random numbers. This program first prompts the user to enter a number between 1 and 1000. Using if/else statements, the program will check to see if the user obtained number is higher/lower than the pre defined random number which is generated by the program. If the user makes a wrong guess, the program will re prompt the user to enter in a new number, where they will have a chance to enter in a new guess. Once the user finally guesses the correct answer, using a do/while loop, the program will ask if they want to play again. If the user selects yes, the game will start over, and a new random number will be generated. If the user selects no, the game will end.
REQUIRED KNOWLEDGE FOR THIS PROGRAM
The "Random" Class
Do/While Loop
How To get Character Input
Custom Setw/Setfill In Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
// ============================================================================ // Author: Kenneth Perkins // Date: Nov 19, 2012 // Taken From: http://programmingnotes.org/ // File: GuessingGame.java // Description: Demonstrates a simple random number guessing game // ============================================================================ import java.util.*; public class GuessingGame { // global variable declarations static Scanner cin = new Scanner(System.in); static Random rand = new Random(); // this is the call to the "Random" class public static void main(String[] args) { // declare & initialize variables char playAgain = 'y'; int userInput = 0; int numGuesses = 0; int randomNumber = rand.nextInt(1000)+1; // ^ get a number from the random generator in the range of 1 - 1000 System.out.println("Welcome to My Programming Notes' Java Program.\n"); // display directions to user System.out.println("I'm thinking of a number between 1 and 1000. Go " + "ahead and make your first guess.\n"); do { // this is the start of the do/while loop System.out.print(">> "); // get data from user userInput = cin.nextInt(); System.out.println(""); // increments the 'numGuesses' variable each time the user // gets the guess wrong ++numGuesses; // if user guess is too high, do this code if (userInput > randomNumber) { System.out.println("Too high! Think lower."); } // if user guess is too low, do this code else if (userInput < randomNumber) { System.out.println("Too low! Think higher."); } // if user guess is correct, do this code else { // display data to user, prompt if user wants to play again System.out.print("You got it, and it only took you " +numGuesses+" trys!\nWould you like to play again (y/n)? "); playAgain = cin.next().charAt(0); // if user wants to play again then re initialize the variables if (playAgain == 'y'|| playAgain == 'Y') { // creates a line seperator if user wants to enter new data System.out.println(""); setwRF("", 60, '-'); numGuesses = 0; System.out.println("\n\nMake a guess (between 1-1000):\n"); // generate a new random number for the user to try & guess randomNumber = rand.nextInt(1000)+1; } } System.out.println(""); } while (playAgain == 'y' || playAgain == 'Y'); // ^ do/while loop ends when user doesnt select 'Y' // display data to user System.out.println("Thanks for playing!!"); }// end of main public static void setwRF(String str, int width, char fill) { System.out.print(str); for (int x = str.length(); x < width; ++x) { System.out.print(fill); } }// end of setwRF }// http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
Once compiled, you should get this as your output:
Welcome to My Programming Notes' Java Program.I'm thinking of a number between 1 and 1000. Go ahead and make your first guess.
>> 900
Too high! Think lower.
>> 300
Too high! Think lower.
>> 100
Too low! Think higher.
>> 200
Too low! Think higher.
>> 350
You got it, and it only took you 5 trys!
Would you like to play again (y/n)? y------------------------------------------------------------
Make a guess (between 1-1000):
>> 300
Too low! Think higher.
>> 600
Too high! Think lower.
>> 500
Too high! Think lower.
>> 400
You got it, and it only took you 4 trys!
Would you like to play again (y/n)? nThanks for playing!!
C++ || Snippet – Simple Linked List Using Delete, Insert, & Display Functions

The following is sample code for a simple linked list, which implements the following functions: “Delete, Insert, and Display.”
The sample code provided on this page is a stripped down version of a more robust linked list class which was previously discussed on this site. Sample code for that can be found here.
It is recommended you check that out as the functions implemented within that class are very useful.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 |
// ============================================================================ // Author: Kenneth Perkins // Date: Aug 18, 2012 // Taken From: http://programmingnotes.org/ // File: SimpleList.cpp // Description: Demonstrates the use of a simple linked list. // ============================================================================ #include <iostream> #include <string> using namespace std; struct node { /* -- you can use different data types here -- instead of just a string char letter; int number; double fNumber; */ string name; node* next; }; // global variables // this is the front of the list node* head = NULL; // function prototype void Insert(string info); void Delete(string info); void Display(); void DestroyList(); int main() { // if you want to insert data into the list // this is one way you can do it, using a 'temp' pointer node* temp = new node; temp->name = "My Programming Notes"; temp->next = NULL; // set the head node to the data thats in the 'temp' pointer head = temp; // display data to the screen cout << head->name <<endl<<endl; // use the insert function to add new data to the list // NOTE: you could have also used the 'insert' function ^ above // to place data into the list Insert("Is An Awesome Site!"); // insert more data into the list Insert("August"); Display(); // delete the selected text from the list Delete("August"); Display(); // destroy the current pointers in the list // after you are finished using them DestroyList(); return 0; }// end of main void Insert(string info) { node* newItem = new node; newItem->name = info; newItem->next = NULL; // if the list is empty, add new item to the front if(head == NULL) { head = newItem; } else // if the list isnt empty, add new item to the end { node* iter = head; while(iter->next != NULL) { iter = iter->next; } iter->next = newItem; } }// end of Insert void Delete(string info) { node* iter = head; // if the list is empty, do nothing if(head == NULL) { return; } // delete the first item in the list else if(head->name == info) { head = head->next; delete iter; } // search the list until we find the desired item else { while(iter->next != NULL) { if(iter->next->name == info) { node* deleteNode = iter->next; iter->next = iter->next->next; delete deleteNode; break; } iter = iter->next; } } }// end of Delete void Display() { node* iter = head; // traverse thru the list, displaying the // text at each node location while(iter != NULL) { cout<<iter->name<<endl; iter = iter->next; } cout<<endl; }// end of Display void DestroyList() { if(head != NULL) { cout << "\n\nDestroying nodes...\n"; while(head != NULL) { node* temp = head; cout << temp->name <<endl; head = head->next; delete temp; } } }// http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
Once compiled, you should get this as your output
My Programming NotesMy Programming Notes
Is An Awesome Site!
August[DELETE THE TEXT "AUGUST"]
My Programming Notes
Is An Awesome Site!Destroying nodes...
My Programming Notes
Is An Awesome Site!
C++ || Snippet – Palindrome Checker Using A Stack & Queue

This page consists of a sample program which demonstrates how to use a stack and a queue to test for a palindrome. This program is great practice for understanding how the two data structures work.
REQUIRED KNOWLEDGE FOR THIS PROGRAM
Structs
Classes
Template Classes - What Are They?
Stacks
Queues
LIFO - Last In First Out
FIFO - First In First Out
#include 'SingleQueue.h'
#include 'ClassStackListType.h'
This program first asks the user to enter in text which they wish to compare for similarity. The data is then saved into the system using the “enqueue” and “push” functions available within the queue and stack classes. After the data is obtained, a while loop is used to iterate through both classes, checking to see if the characters at each location within both classes are the same. If the text within both classes are the same, it is a palindrome.
NOTE: This program uses two custom template.h classes. To obtain the code for both class, click here and here.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
// ============================================================================ // Author: Kenneth Perkins // Date: Jul 22, 2012 // Taken From: http://programmingnotes.org/ // File: palindrome.cpp // Description: Demonstrates a palindrome checker using a stack & queue // ============================================================================ #include <iostream> #include <cctype> #include "SingleQueue.h" #include "ClassStackListType.h" using namespace std; int main() { // declare variable char singleChar = ' '; bool isPalindrome = true; SingleQueue<char> queue; StackListType<char> stack; // get data from user, then place them into the // queue and stack for storage. This loop also // displays the user input back to the screen via cout cout <<"Enter in some text to see if its a palindrome: "; while(cin.get(singleChar) && singleChar != '\n') { cout<<singleChar; queue.EnQueue(toupper(singleChar)); stack.Push(toupper(singleChar)); } // determine if the string is a palindrome while((!queue.IsEmpty() && !stack.IsEmpty()) && isPalindrome) { if(queue.Front() != stack.Top()) { isPalindrome = false; } else { queue.DeQueue(); stack.Pop(); } } // display results to the screen if(isPalindrome) { cout<<" is a palindrome!\n"; } else { cout<<" is NOT a palindrome..\n"; } return 0; }// http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
Once compiled, you should get this as your output
(Note: The code was compiled 2 separate times to demonstrate different output)
====== RUN 1 ======Enter in some text to see if its a palindrome: StEP on No pETS
StEP on No pETS is a palindrome!
====== RUN 2 ======
Enter in some text to see if its a palindrome: Hello World
Hello World is NOT a palindrome..
C++ || Convert Numbers To Words Using A Switch Statement

This program demonstrates more practice using arrays and switch statements.
REQUIRED KNOWLEDGE FOR THIS PROGRAM
Integer Arrays
Cin.get
Isdigit
For loops
While Loops
Switch Statements - How To Use
Using “cin.get(),” this program first asks the user to enter in a number (one at a time) that they wish to translate into words. If the text which was entered into the system is a number, the program will save the user input into an integer array. If the text is not a number, the input is discarded. After integer data is obtained, a for loop is used to traverse the integer array, passing the data to a switch statement, which translates the number to text.
This program is very simple, so it does not have the ability to display any number prefixes. As a result, if the number “1858” was entered into the system, the program would output the converted text: “One Eight Five Eight.”
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
#include <iostream> #include <cctype> using namespace std; int main() { // declare variables int numberArry[50]; int numElems=0; char singleNum=' '; // ask the user for a number cout<<"Enter number: "; // get data from the user, one character at a time while(cin.get(singleNum) && singleNum != 'n') { // only numbers will be saved into the array, everything // else is ignored if(isdigit(singleNum)) { // this converts a char into an integer using ascii values numberArry[numElems] = (singleNum)-'0'; ++numElems; } } cout<<endl; // using the data from the array, display the // numbers to the screen using a switch statement for(int index=0; index < numElems; ++index) { switch(numberArry[index]) { case 0 : cout<<"Zero "; break; case 1 : cout<<"One "; break; case 2: cout<<"Two "; break; case 3: cout<<"Three "; break; case 4: cout<<"Four "; break; case 5: cout<<"Five "; break; case 6: cout<<"Six "; break; case 7: cout<<"Seven "; break; case 8: cout<<"Eight "; break; case 9: cout<<"Nine "; break; default: cout<<"nERROR!n"; break; } } cout<<endl; return 0; }// http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
Once compiled, you should get this as your output
Note: The code was compiled four separate times to display different output
======= Run #1 =======Enter number: 77331
Seven Seven Three Three One
======= Run #2 =======
Enter number: 234-43-1275
Two Three Four Four Three One Two Seven Five
======= Run #3 =======
Enter number: 1(800) 123-5678
One Eight Zero Zero One Two Three Five Six Seven Eight
======= Run #4 =======
Enter number: This 34 Is 24 A 5 Number 28
Three Four Two Four Five Two Eight
C++ || Char Array – Palindrome Number Checker Using A Character Array, Strlen, Strcpy, & Strcmp

The following is a palindromic number checking program, which demonstrates more use of character array’s, Strlen, & Strcmp.
Want sample code for a palindrome checker which works for numbers and words? Click here.
REQUIRED KNOWLEDGE FOR THIS PROGRAM
Character Arrays
How to reverse a character array
Palindrome - What is it?
Strlen
Strcpy
Strcmp
Isdigit
Atoi - Convert a char array to a number
Do/While Loops
For Loops
This program first asks the user to enter a number that they wish to compare for similarity. If the number which was entered into the system is a palindrome, the program will prompt a message to the user via cout. This program determines similarity by using the strcmp function to compare two arrays together. Using a for loop, this program also demonstrates how to reverse a character array, aswell as demonstrates how to determine if the text contained in a character array is a number or not.
This program will repeatedly prompt the user for input until an “exit code” is obtained. The designated exit code in this program is the number 0 (zero). So the program will not stop asking for user input until the number 0 is entered into the program.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 |
// ============================================================================ // Author: Kenneth Perkins // Date: Jul 10, 2012 // Taken From: http://programmingnotes.org/ // File: palindrome.cpp // Description: Palindrome number checker // ============================================================================ #include <iostream> #include <cctype> #include <cstring> #include <cstdlib> using namespace std; // function prototypes void Reverse(char arry[]); bool IsArryANum(char arry[]); // constant, which is the exit value const char* EXIT_VALUE = "0"; int main() { // declare variables char arry[80]; char arryReversed[80]; do{// get data from user using do/while loop cout<<"\nEnter a positive integer, or ("<<EXIT_VALUE<<") to exit: "; cin >> arry; if(atoi(arry) < 0) // check for negative numbers { cout <<"\n*** Error: "<<arry<<" must be greater than zero\n"; } else if(!IsArryANum(arry)) // check for any letters { cout <<"\n*** Error: "<<arry<<" is not an integer\n"; } else if(strcmp(EXIT_VALUE, arry) == 0) // check for "exit code" { cout <<"\nExiting program...\n"; } else // if all else is good, determine if number is a palindrome { // copy the user input from the first array (arry) // into the second array (arryReversed) strcpy(arryReversed, arry); // function call to reverse the contents inside the // "arryReversed" array to check for similarity Reverse(arryReversed); cout <<endl<<arry; // use strcmp to determine if the two arrays are the same if(strcmp(arryReversed, arry) == 0) { cout <<" is a Palindrome..\n"; } else { cout <<" is NOT a Palindrome!\n"; } } }while(strcmp(EXIT_VALUE, arry) != 0); // keep going until user enters the exit value cout <<"\nBYE!\n"; return 0; }// end of main void Reverse(char arry[]) { // get the length of the current word in the array index int length = strlen(arry)-1; // increment thru each letter within the current char array index // reversing the order of the array for (int currentChar=0; currentChar < length; --length, ++currentChar) { // copy 1st letter in the array index into temp char temp = arry[currentChar]; // copy last letter in the array index into the 1st array index arry[currentChar] = arry[length]; // copy temp into last array index arry[length] = temp; } }// end of Reverse bool IsArryANum(char arry[]) { // LOOP UNTIL U REACH THE NULL CHARACTER, // AKA THE END OF THE CHAR ARRAY for(int x=0; arry[x]!='\0'; ++x) { // if the current char isnt a number, // exit the loop & return false if(!isdigit(arry[x])) { return false; } } return true; }// http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
Once compiled, you should get this as your output
Enter a positive integer, or (0) to exit: L33T*** error: "L33T" is not an integer
Enter a positive integer, or (0) to exit: -728
*** error: -728 must be greater than zero
Enter a positive integer, or (0) to exit: 1858
1858 is NOT a Palindrome!
Enter a positive integer, or (0) to exit: 7337
7337 is a Palindrome..
Enter a positive integer, or (0) to exit: 0
Exiting program...
BYE!