





Monthly Archives: August 2013
C++ || Multi-Hash Interprocess Communication Using Fork, Popen, & Pipes

The following is another homework assignment which was presented in an Operating Systems Concepts class. Using two pipes, the following is a program which implements the computing of hash values on a file using the MD5, SHA1, SHA224, SHA256, SHA384, and SHA512 hashing algorithms provided on Unix based systems.
REQUIRED KNOWLEDGE FOR THIS PROGRAM
==== 1. OVERVIEW ====
Hash algorithms map large data sets of variable length (e.g. files), to data sets of a fixed length. For example, the contents of a 1GB file may be hashed into a single 128-bit integer. Many hash algorithms exhibit an important property called an avalanche effect – slight changes in the input data trigger significant changes in the hash value.
Hash algorithms are often used for verifying the integrity of files downloaded from the WEB. For example, websites hosting a file usually post the hash value of the file using the MD5 hash algorithm. By doing this, the user can then verify the integrity of the downloaded file by computing the MD5 algorithm on their own, and compare their hash value against the hash value posted on the website. The user will know if the download was valid only if the two hash values match.
==== 2. TECHNICAL DETAILS ====
The following implements a program for computing the hash value of a file using the MD5, SHA1, SHA224, SHA256, SHA384, and SHA512 hashing algorithms provided on Unix based systems.
This program takes the name of the target file being analyzed as a command line argument, and does the following:
1. Check to make sure the file exists.
2. Create two pipes.
3. Create a child process.
4. The parent transmits the name of the file to the child (over the first pipe).
5. The child receives the name of the file and computes the hash of the file using the MD5 algorithm (using Linux program md5sum).
6. The child transmits the computed hash to the parent (over the second pipe) and terminates.
7. The parent receives the hash, prints it, and calls wait().
8. Repeat the same process starting with step 3, but using algorithms SHA1...SHA512.
9. The parent terminates after all hashes have been computed.
The use of the popen function is used in order to launch the above programs and capture their output into a character array buffer.
This program also uses two pipes. The two pipes created are the following:
(1) Parent to child pipe: Used by the parent to transfer the name of the file to the child. The parent writes to this pipe and the child reads it.(2) Child to parent pipe: Used by the child to transfer the computed hashes to the parent. The child writes to this pipe and the parent reads it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 |
// ============================================================================= // Author: K Perkins // Date: Aug 20, 2013 // Taken From: http://programmingnotes.org/ // File: Multihash.cpp // Description: Hash algorithms map large data sets of variable length (e.g. // files), to data sets of a fixed length. For example, contents of a // 1GB file may be hashed into a single 128-bit integer. Using 2 pipes, // this program implements the computing of hash values on a file using // the MD5, SHA1, SHA224, SHA256, SHA384, and SHA512 hashing algorithms. // // The two pipes created are the following: // (1) Parent to child pipe: Used by the parent to transfer the name of // the file to the child. The parent writes to this pipe and the // child reads it. // (2) Child to parent pipe: Used by the child to transfer the computed // hashes to the parent. The child writes to this pipe and the // parent reads it. // ============================================================================= #include <iostream> #include <fstream> #include <cstdlib> #include <cstring> #include <unistd.h> #include <sys/wait.h> using namespace std; // compile: g++ Multihash.cpp -o Multihash // run: ./Multihash <file name> // parentToChild = pipe for parent to child communication // childToParent = pipe for child to parent communication int parentToChild[2]; int childToParent[2]; // names of the hash programs const char hashAlgs[6][10] = {"md5sum", "sha1sum", "sha224sum", "sha256sum", "sha384sum", "sha512sum"}; // read end of pipe const int READ_END = 0; // write end of pipe const int WRITE_END = 1; // number of hash programs const int NUM_HASH_ALGS = sizeof(hashAlgs)/sizeof(hashAlgs[0]); // maximum length of hash value const int HASH_LENGTH = 1000; // maximum length of file name const int FILENAME_LENGTH = 100; // child function which computes the hash of a file and // returns the value back to the parent // @param 'hashAlg' == the name of the hash program void ComputeHash(const char hashAlg[]); int main(int argc, char* argv[]) { // declare variables ifstream infile; // used to see if file exists char hashValue[HASH_LENGTH]; // hash value which child passes to parent // check to see if theres enough commandline args if(argc < 2) { cerr<<"n** ERROR - NOT ENOUGH ARGUMENTS!n" <<"nUSAGE: "<<argv[0]<<" <FILE NAME>n"; exit(1); } // try to open file infile.open(argv[1]); // if file doesnt exist, then exit if(infile.fail()) { cerr<<"n** ERROR!n" <<"Cant find the file ""<<argv[1]<<""!nn"; exit(1); } infile.close(); // start the piping process for(int currentAlg = 0; currentAlg < NUM_HASH_ALGS; ++currentAlg) { // create pipes if((pipe(parentToChild) < 0) || (pipe(childToParent) < 0)) { cerr << "npipe failedn"; exit(1); } // create & fork a child pid_t pid = fork(); // make sure fork succeeded if(pid < 0) { cerr << "nfork failedn"; exit(1); } // child process else if(pid == 0) { ComputeHash(hashAlgs[currentAlg]); } // parent process else { // close selected pipes ends close(parentToChild[READ_END]); close(childToParent[WRITE_END]); // pass the filename to the child write(parentToChild[WRITE_END], argv[1], strlen(argv[1])+1); close(parentToChild[WRITE_END]); // read the incoming hash value from the child read(childToParent[READ_END], hashValue, sizeof(hashValue)); close(childToParent[READ_END]); // wait for child to complete wait(NULL); // display current hash to the screen cout<<"Hash Algorithm #"<<currentAlg+1<<":n"<<hashAlgs[currentAlg] <<" - HASH VALUE: "<<hashValue<<endl; // reset hash buffer memset(hashValue, (char)NULL, sizeof(hashValue)); } } cerr<<"The parent process is now exiting...n"; return 0; }// end of main void ComputeHash(const char hashAlg[]) { // declare variables char recievedFileName[FILENAME_LENGTH]; // saves recieved filename char cmdLine[FILENAME_LENGTH]; // saves command line for popen char hashOutput[HASH_LENGTH]; // saves final hash output FILE* popenOutput; // popen file pointer // close selected pipes ends close(parentToChild[WRITE_END]); close(childToParent[READ_END]); // get filename from parent read(parentToChild[READ_END], recievedFileName, sizeof(recievedFileName)); close(parentToChild[READ_END]); // construct command line argument to pass to popen strncpy(cmdLine, hashAlg, sizeof(cmdLine)); strncat(cmdLine, " ", sizeof(cmdLine)); strncat(cmdLine, recievedFileName, sizeof(cmdLine)); // get has value for current hash prog popenOutput = popen(cmdLine, "r"); // make sure that popen succeeded if(!popenOutput) { cerr<<"npopen failedn"; exit(1); } // set hash buffer to all NULLS memset(hashOutput, (char)NULL, sizeof(hashOutput)); // read program output into buffer fread(hashOutput, sizeof(char), sizeof(char)*sizeof(hashOutput), popenOutput); // close popen buffer pclose(popenOutput); // pass hash value back to parent write(childToParent[WRITE_END], hashOutput, strlen(hashOutput)+1); close(childToParent[WRITE_END]); // exit 'AKA' kill child exit(0); }// http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
Using the following example input file located here, the following is sample output:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
Hash Algorithm #1: md5sum - HASH VALUE: cd2f02cc5e50bd08d83cef630a32d7d6 INPUT_Dictionary_programmingnotes_freeweq_com.txt Hash Algorithm #2: sha1sum - HASH VALUE: 1e1d2fd77b331fc2b2f24822fdf2133f3678d662 INPUT_Dictionary_programmingnotes_freeweq_com.txt Hash Algorithm #3: sha224sum - HASH VALUE: bf69da0f9f9990cece8dd6800a25a9faca5381c0c62e0667c258e8d5 INPUT_Dictionary_programmingnotes_freeweq_com.txt Hash Algorithm #4: sha256sum - HASH VALUE: a8cd7a082ce571f7e66bc4d5eea8f71e7e455735922c90c060580b51d43593ec INPUT_Dictionary_programmingnotes_freeweq_com.txt Hash Algorithm #5: sha384sum - HASH VALUE: a564df501470a43eebb51c28f83ab07090e39c434fc40bf496622f536c525140301633d6513dec83ea512bcb38c4e2e6 INPUT_Dictionary_programmingnotes_freeweq_com.txt Hash Algorithm #6: sha512sum - HASH VALUE: e686a709b3025f8b21fd6d40ce92f741dd8644335e935baced86098ff3e7278b5443e28f02fa886e7c0cd391ce6e8aa91842a6de29535a40453d41862a0bc1c7 INPUT_Dictionary_programmingnotes_freeweq_com.txt The parent process is now exiting... |
C++ || Snippet – How To Use Popen & Save Results Into A Character Array

The following is sample code which demonstrates the use of the “popen” function call on Unix based systems.
The “popen” function call opens a process by creating a pipe, forking, and invoking the shell. It does this by executing the command specified by the incoming string function parameter. It creates a pipe between the calling program and the executed command, and returns a pointer to a stream that can be used to either read from or write to the pipe.
The following example demonstrates how to save the results of the popen command into a char array.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
// ============================================================================ // Author: Kenneth Perkins // Date: Aug 20, 2013 // Taken From: http://programmingnotes.org/ // File: PopenExample.cpp // Description: Demonstrate the use of the popen() command and demonstrate // how to save the results into a char array. // ============================================================================ #include <iostream> #include <cstdio> #include <cstring> #include <cstdlib> using namespace std; // the maximum output size const int MAX_OUTPUT_SIZE = 1000; int main(int argc, char* argv[]) { // declare variables char buffer[MAX_OUTPUT_SIZE]; // a char array to display the popen output FILE* progOutput; // a file pointer representing the popen output // launch the "md5sum" program to compute the MD5 hash of // the file "/bin/ls" and save it into the file pointer progOutput = popen("md5sum /bin/ls", "r"); // make sure that popen succeeded if (!progOutput) { perror("popen"); exit(1); } // reset buffer to all NULLS memset(buffer, (char)NULL, sizeof(buffer)); // read the popen output into the char array buffer if (fread(buffer, sizeof(char), sizeof(char) * sizeof(buffer), progOutput) < 0) { perror("fread"); exit(1); } // close the file pointer representing the popen output if (pclose(progOutput) < 0) { perror("pclose"); exit(1); } cout << "Program output: " << buffer << endl; return 0; }// http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
The following is sample output:
Program output: fa97c59cc414e42d4e0e853ddf5b4745 /bin/ls
C++ || Serial & Parallel Multi Process File Downloader Using Fork & Execlp

The following is another homework assignment which was presented in an Operating Systems Concepts class. The following are two multi-process programs using commandline arguments, which demonstrates more practice using the fork() and execlp() system calls on Unix based systems.
==== 1. OVERVIEW ====
File downloaders are programs used for downloading files from the Internet. The following programs listed on this page implement two distinct type of multi-process downloaders:
1. a serial file downloader which downloads files one by one.
2. a parallel file downloader which dowloads multiple files in parallel.
In both programs, the parent process first reads a file via the commandline. This file which is read is the file that contains the list of URLs of the files to be downloaded. The incoming url file that is read has the following format:
[URL1]
[URL2]
.
.
.
[URLN]
Where [URL] is an http internet link with a valid absolute file path extension.
(i.e: http://newsimg.ngfiles.com/270000/270173_0204618900-cc-asmbash.jpg)
After the url file is parsed, next the parent process forks a child process. Each created child process uses the execlp() system call to replace its executable image with that of the “wget” program. The use of the wget program performs the actual file downloading.
==== 2. SERIAL DOWNLOADER ====
The serial downloader downloads files one at a time. After the parent process has read and parsed the incoming url file from the commandline, the serial downloader proceeds as follows:
1. The parent forks off a child process.
2. The child uses execlp("/usr/bin/wget", "wget", [URL STRING1], NULL) system call in order to replace its program with wget program that will download the first file in urls.txt (i.e. the file at URL).
3. The parent executes a wait() system call until the child exits.
4. The parent forks off another child which downloads the next file specified in url.txt.
5. Repeat the same process until all files are downloaded.
The following is implemented below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
// ============================================================================ // Author: Kenneth Perkins // Date: Aug 19, 2013 // Taken From: http://programmingnotes.org/ // File: Serial.cpp // Description: File downloaders are programs used for downloading files // from the Internet. Using the fork() & execlp("wget") command, the // following is a multi-process serial file downloader which reads an // input file containing url file download links as a commandline // argument and downloads the files located on the internet one by one. // ============================================================================ #include <iostream> #include <cstring> #include <fstream> #include <cstdlib> #include <unistd.h> #include <sys/wait.h> using namespace std; // compile & run // g++ Serial.cpp -o Serial // ./Serial urls.txt int main(int argc, char* argv[]) { // declare variables pid_t pid = -1; int urlNumber = 0; char urlName[256]; ifstream infile; // check if theres enough command line args if(argc < 2) { cout <<"\nERROR -- NOT ENOUGH ARGS!" <<"\n\nUSAGE: "<<argv[0]<<" <file containing url downloads>\n\n"; exit(1); } // try to open the file containing the download url links // exit if the url file is not found infile.open(argv[1]); if(infile.fail()) { cout <<"\nERROR -- "<<argv[1]<<" NOT FOUND!\n\n"; exit(1); } // get download url links from the file while(infile.getline(urlName, sizeof(urlName))) { ++urlNumber; // fork another process pid = fork(); if(pid < 0) { // ** error occurred perror("fork"); exit(1); } else if(pid == 0) { // ** child process cout <<endl<<"** URL #"<<urlNumber <<" is currently downloading... **\n\n"; execlp("/usr/bin/wget", "wget", urlName, NULL); } else { // ** parent process // parent will wait for the child to complete wait(NULL); cout <<endl<<"-- URL #"<<urlNumber<<" is complete! --\n"; } } infile.close(); cout <<endl<<"The parent process is now exiting...\n"; return 0; }// http://programmingnotes.org/ |
Since the serial downloader downloads files one at a time, that can become very slow. That is where the parallel downloader comes in handy!
==== 3. PARALLEL DOWNLOADER ====
The parallel downloader downloads files all at once and is implemented much like the serial downloader. The parallel downloader proceeds as follows:
1. The parent forks off n children, where n is the number of URLs in url.txt.
2. Each child executes execlp("/usr/bin/wget", "wget", [URL STRING], NULL) system call where eachis a distinct URL in url.txt.
3. The parent calls wait() (n times in a row) and waits for all children to terminate.
4. The parent exits.
The following is implemented below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 |
// ============================================================================ // Author: Kenneth Perkins // Date: Aug 19, 2013 // Taken From: http://programmingnotes.org/ // File: Parallel.cpp // Description: File downloaders are programs used for downloading files // from the Internet. Using the fork() & execlp("wget") command, the // following is a multi-process parallel file downloader which reads an // input file containing url file download links as a commandline // argument and downloads the files located on the internet all at once. // ============================================================================ #include <iostream> #include <cstring> #include <fstream> #include <cstdlib> #include <unistd.h> #include <sys/wait.h> using namespace std; // compile & run // g++ Parallel.cpp -o Parallel // ./Parallel urls.txt int main(int argc, char* argv[]) { // declare variables pid_t pid = -1; int urlNumber = 0; char urlName[256]; ifstream infile; // check if theres enough command line args if(argc < 2) { cout <<"\nERROR -- NOT ENOUGH ARGS!" <<"\n\nUSAGE: "<<argv[0]<<" <file containing url downloads>\n\n"; exit(1); } // try to open the file containing the download url links // exit if the url file is not found infile.open(argv[1]); if(infile.fail()) { cout <<"\nERROR -- "<<argv[1]<<" NOT FOUND!\n\n"; exit(1); } // get download url links from the file while(infile.getline(urlName, sizeof(urlName))) { ++urlNumber; // fork another process pid = fork(); if(pid < 0) { // ** error occurred perror("fork"); exit(1); } else if(pid == 0) { // ** child process cout <<endl<<"** URL #"<<urlNumber <<" is currently downloading... **\n\n"; execlp("/usr/bin/wget", "wget", urlName, NULL); } } infile.close(); while(urlNumber > 0) { // ** parent process // parent will wait for the child to complete wait(NULL); cout <<endl<<"-- URL #"<<urlNumber<<" is complete! --\n"; --urlNumber; } cout <<endl<<"The parent process is now exiting...\n"; return 0; }// http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
Also note, while the parallel downloader executes, the outputs from different children may intermingle.
C++ || Snippet – How To Use Fork & Pipe For Interprocess Communication
The following is sample code which demonstrates the use of the fork, read, and write function calls for use with pipes on Unix based systems.
A pipe is a mechanism for interprocess communication. Data written to a pipe by one process can be read by another process. Creating a pipe is achieved by using the pipe function, which creates both the reading and writing ends of the pipe file descriptor.
In typical use, a parent process creates a pipe just before it forks one or more child processes. The pipe is then used for communication between either the parent or child processes, or between two sibling processes.
A real world example of this kind of communication can be seen in all operating system terminal shells. When you type a command in a shell, it will spawn the executable represented by that command with a call to fork. A pipe is opened to the new child process, and its output is read and printed by the terminal.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
// ============================================================================ // Author: Kenneth Perkins // Date: Aug 19, 2013 // Taken From: http://programmingnotes.org/ // File: ForkPipeExample.cpp // Description: Demonstrate the use of the fork() and pipe() command for // parent and child interprocess communication. // ============================================================================ #include <iostream> #include <cstdlib> #include <cstring> #include <sys/wait.h> #include <unistd.h> using namespace std; // global variables const int BUFFER_SIZE = 256; const int READ_END = 0; const int WRITE_END = 1; int main() { // declare variables int fd[2]; // pipe file descriptor pid_t pid = -1; char writeMsg[BUFFER_SIZE] = "Greetings From Your Parent!"; char readMsg[BUFFER_SIZE]; // create a pipe if(pipe(fd) < 0) { perror("pipe"); exit(1); } cout <<"\nParent is forking a child." << endl; // create a duplicate process of this current program pid = fork(); // exit if something went wrong with the fork if(pid < 0) { perror("fork"); exit(1); } // this code only gets executed by the child process else if(pid == 0) { cout <<"\nStarting the child process..\n\n"; // close the "write" end b/c we arent using it close(fd[WRITE_END]); // get data from the pipe using the read() function read(fd[READ_END], readMsg, sizeof(readMsg)); // close the "read" end close(fd[READ_END]); cout <<"Message from the parent via the pipe: "<<readMsg<<endl; } // the parent process executes here else { cout <<"\nParent is now waiting for child id #"<<pid<<" to complete..\n"; // close the "read" end b/c we arent using it close(fd[READ_END]); // write data on pipe write(fd[WRITE_END], writeMsg, strlen(writeMsg)+1); // close the "write" end close(fd[WRITE_END]); // use the "wait" function to wait for the child to complete wait(NULL); cout <<"\nThe child process is complete and has terminated!\n"; } // NOTE: this message gets displayed twice - Why?! cout <<"\nProgram is now exiting...\n"; return 0; }// http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
The following is sample output:
Parent is forking a child.
Parent is now waiting for child id #12776 to complete..Starting the child process..
Message from the parent via the pipe: Greetings From Your Parent!
Program is now exiting...
The child process is complete and has terminated!
Program is now exiting...
C++ || Snippet – How To Use Fork & Execlp For Interprocess Communication

The following is sample code which demonstrates the use of the “fork” and “execlp” function calls on Unix based systems.
The “fork” function call creates a new process by duplicating the calling process; or in more simpler terms, it creates a duplicate process (a child) of the calling (parent) process.
This new process, referred to as the child, is an exact duplicate of the calling process, referred to as the parent.
The “execlp” function call is part of a family of functions which replaces a current running process image with a new process image. That means by using the “execlp” function call, you are basically replacing the entire current running process with a new user defined program.
Though fork and execlp are not required to be used together, they are often used in conjunction with one another as a way of creating a new program running as a child of another process.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
// ============================================================================ // Author: Kenneth Perkins // Date: Aug 19, 2013 // Taken From: http://programmingnotes.org/ // File: ForkExample.cpp // Description: Demonstrate the use of the fork() command for parent and // child process manipulation. // ============================================================================ #include <iostream> #include <cstdlib> #include <sys/wait.h> #include <unistd.h> using namespace std; int main() { // declare variable pid_t pid = -1; cout <<"\nParent is forking a child." << endl; // create a duplicate process of this current program pid = fork(); // exit if something went wrong with the fork if(pid < 0) { perror("fork"); exit(1); } // this code only gets executed by the child process else if(pid == 0) { cout <<"\nStarting the child process..\n" << endl; // NOTE: the "execlp" function replaces the current // child process with the terminal "ls" command. // the child process finally dies after the "execlp" // function is complete execlp("/bin/ls", "ls", "-l", NULL); // "ls -l" command cout <<"\nNOTE: This never gets executed - Why?!"; } // the parent process executes here else { cout <<"\nParent is now waiting for child id #"<<pid<<" to complete.." << endl; // use the "wait" function to wait for the child to complete wait(NULL); cout <<"\nThe child process is complete and has terminated!\n"; } cout <<"\nParent is now exiting...\n"; return 0; }// http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
The following is sample output:
Parent is forking a child.
Parent is now waiting for child id #10872 to complete..Starting the child process..
total 1466
-rw-r--r-- 1 admin admin 468 Apr 27 2012 nautilus-computer.desktop
-rwxrwxr-x 1 admin admin 9190 Aug 19 15:17 ForkExample
-rw-rw-r-- 1 admin admin 1640 Aug 19 15:17 ForkExample.cppThe child process is complete and has terminated!
Parent is now exiting...
Python || Aku Aku Snake Game Using Pygame

The following is another homework assignment which was presented in an Introduction to Game Design and Production class. This project is an implementation of the classic “Snake” game using Python 3.2 and Pygame 1.9.2a0.
REQUIRED KNOWLEDGE FOR THIS PROGRAM
Pygame - How To Install
Pygame - Download Here
How To Use Pygame
How To Create Executable Python Programs
Aku Aku Snake! Source Code - Click Here To Download
Aku Aku Snake! Executable File - Click Here To Download
==== 1. DESCRIPTION ====
Aku Aku Snake is a new take on the classic “snake” game. It features ten levels, with characters and sounds taken from the PlayStation hit: “Crash Bandicoot 2: Cortex Strikes Back.” The purpose of this game is to successfully complete all ten levels in the fewest amount of retries possible.
To advance in the game, each round the player must consume a specified number of fruit items. Once the required score is obtained during each round, a new one is started. This process is repeated until the player finishes all ten levels. But watch out! The game gets harder as the game progresses.
==== 2. USAGE ====
This game utilizes the python “pygame” module. To play this game, it is assumed that the user already has python 3 and pygame installed on their computer. If that is not the case, here are documents explaining how to obtain the necessary resources for play.
How to install Python:
How to install Pygame:
After the required resources are obtained, to start the game, the easiest way this to do would be to extract the entire .zip file into the directory of your choice, and to simply run the “main.py” source file through the python interpreter. Once the “main.py” source file is ran through the python interpreter, the game should automatically start.
NOTE: Python and Pygame are not needed to play the executable file!
==== 3. EXTERNAL DEPENDENCIES ====
Other than the pygame module and the “main.py” file mentioned above, there are eight other source files this program depends on. The additional source files should be saved within the “libs” folder, which is located in the directory: “data -> libs”
The following is a brief description of each additional source file.
• “gameBoard.py” sets up the game board and background images for display. This class also reads files (images/fonts) from the “img” & “fnt” directory for use within this program.
• “gameMusic.py” sets up the game sounds and music. This class also reads files (.ogg) from the “snd” directory for use within this program.
• “gameSave.py” sets up the game to have the ability to save its current status. This class uses the “pickle” module to save the players current progress to a file.
• “snake.py” sets up the snake for display on the game board. This class also reads files (images) from the “img” directory for use within this program.
• “fruit.py” sets up the fruit for display on the game board. This class also reads files (images) from the “img” directory for use within this program.
• “enemy.py” sets up the enemies for display on the game board. This class also reads files (images) from the “img” directory, and uses the “spriteStripAnim” class for use within this program.
• “spriteSheet.py” handles sprite sheet animations.
• “spriteStripAnim.py” extends the spriteSheet.py module, providing an iterator (iter() and next() methods), and a __add__() method for joining strips, which comes in handy when a strip wraps to the next row.
These additional files are located within the directory: “data -> libs” folder.
==== 4. FEATURES ====
This game features various colorful images and background music which are taken from the original Crash Bandicoot game. Each level in this game features background music that are unique to each level.
The most useful feature implemented in this game is the “save game” element, which allows a player to save their current progress at any moment during gameplay. This allows a player to save their current status and continue playing the game at a later date if they desire.
To save the game, during gameplay simply click on the boss image in the upper right corner. Once the save is complete, a sound jingle will play confirming the successful save.
This game also features two modes of operation: “Easy” and “Hard” mode. When easy mode is selected, the game saves the user’s current game progress every time they die, but when hard mode is selected, that feature is turned off and the user HAS to save their current progress manually, or else it will be lost after each death.
Here are screenshots of the game during play. (on all images, click to enlarge)
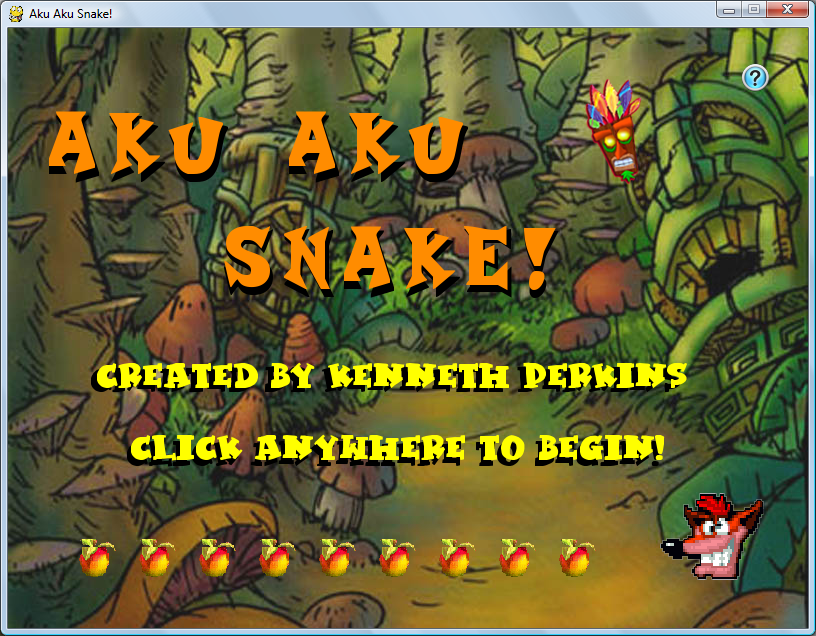
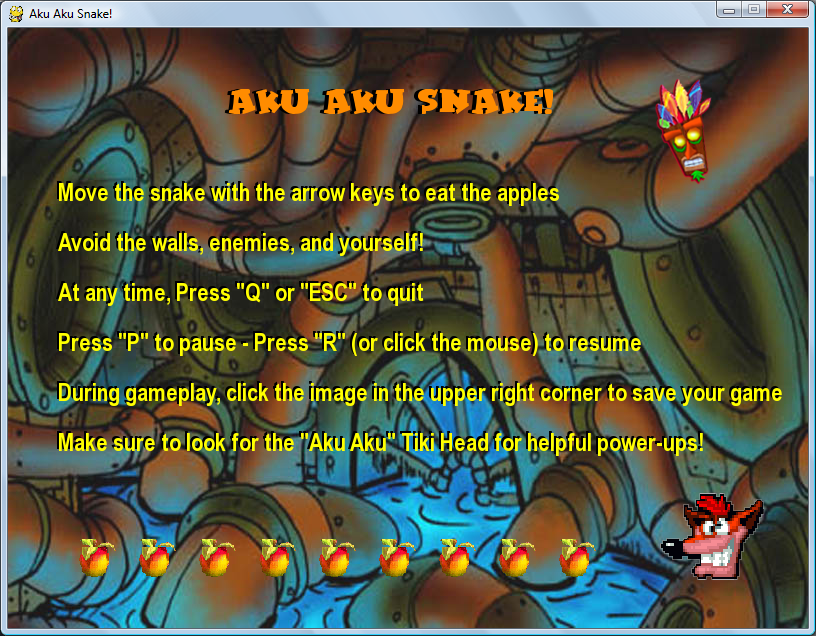

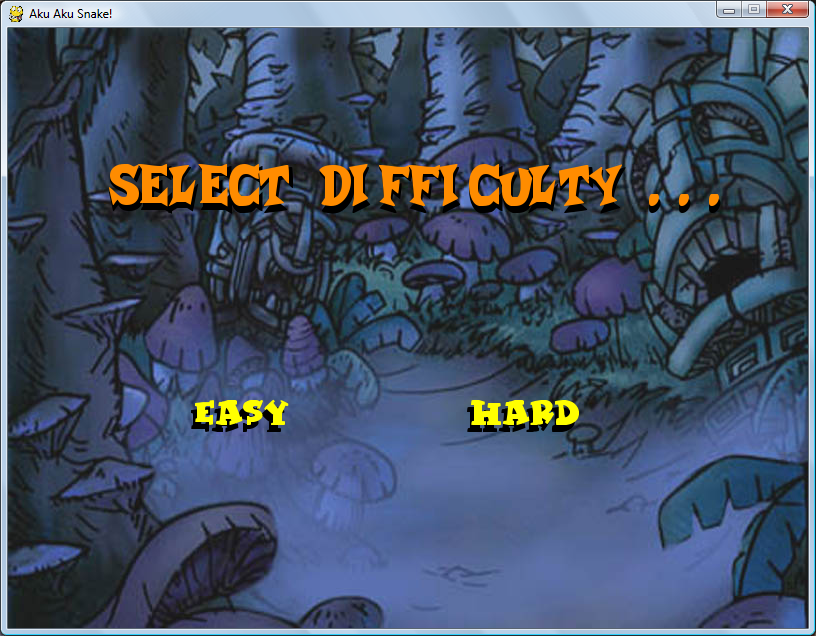

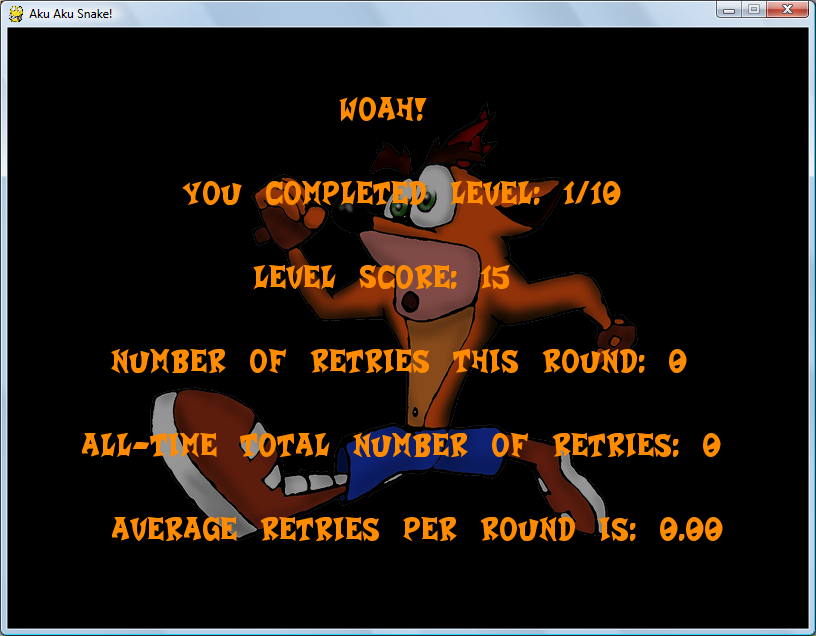
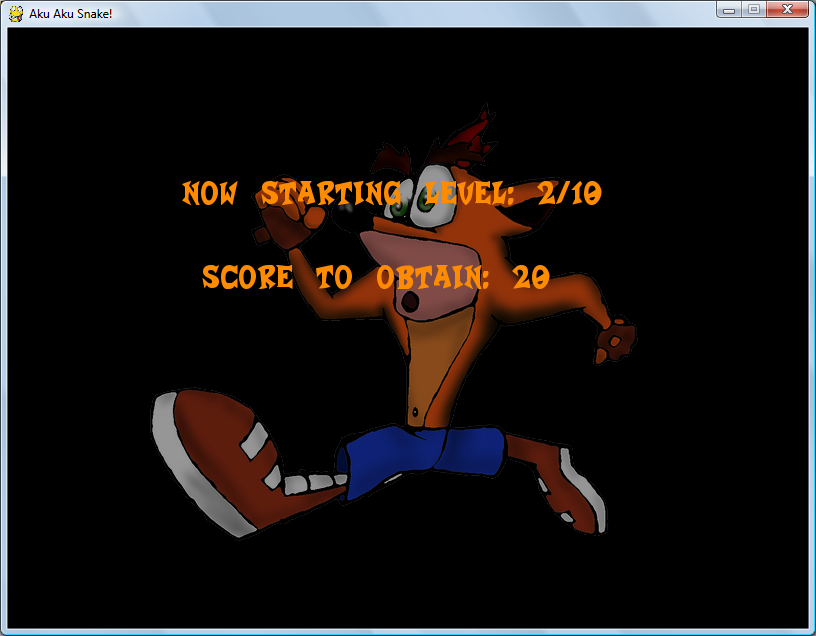
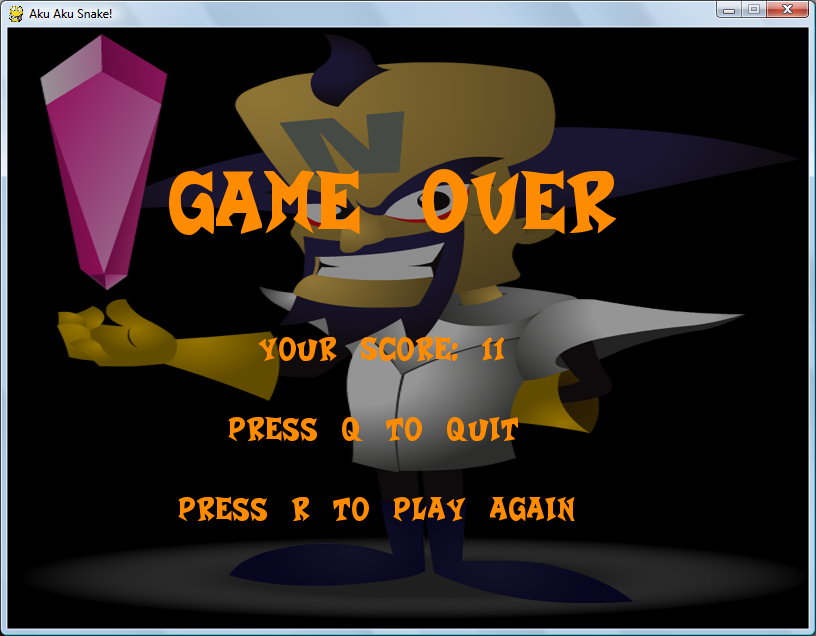


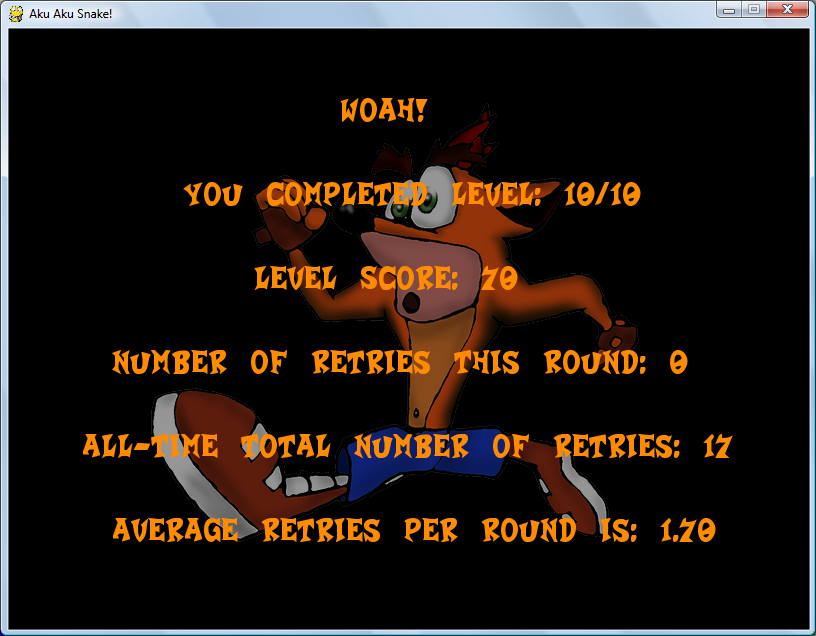
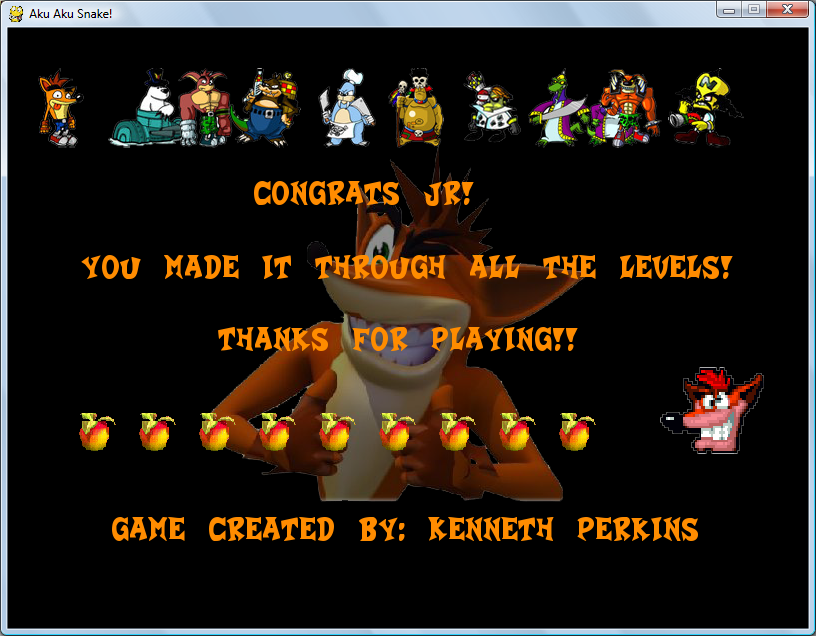
==== 5. DOWNLOAD AND PLAY ====
• Aku Aku Snake! Source Code - Click Here To Download
• Aku Aku Snake! Executable File - Click Here To Download
NOTE: Python and Pygame are not needed to play the executable file!
Python || Brainy Memory Game Using Pygame

The following is another homework assignment which was presented in an Introduction to Game Design and Production class. This project is an implementation of the classic “Memory” game using Python 3.2 and Pygame 1.9.2a0.
REQUIRED KNOWLEDGE FOR THIS PROGRAM
Pygame - How To Install
Pygame - Download Here
How To Use Pygame
How To Create Executable Python Programs
Brainy Memory Game Source Code - Click Here To Download
Brainy Memory Game Executable File - Click Here To Download
==== 1. DESCRIPTION ====
Brainy Memory Game is a mind stimulating educational card game in which an assortment of cards are laid face down on a surface, and the player tries to find and uncover two identical pairs. If the two selected cards match, they are removed from gameplay. If the two selected cards do not match, both of the cards are turned back over, and the process repeats until all identical matching cards have been uncovered! The object of this game is to find identical pairs of two matching cards in the fewest number of turns possible. This game can be played alone or with multiple players, and is especially challenging for children and adults alike.
==== 2. USAGE ====
This game utilizes the python “pygame” module. To play this game, it is assumed that the user already has python and pygame installed on their computer. If that is not the case, here are documents explaining how to obtain the necessary resources for play.
How to install Python:
How to install Pygame:
After the required resources are obtained, to start the game, the easiest way to do this would be to extract the entire .zip file into the directory of your choice, and to simply run the “memory.py” source file through the python interpreter. Once the “memory.py” source file is ran through the python interpreter, the game should automatically start.
NOTE: Python and Pygame are not needed to play the executable file!
==== 3. EXTERNAL DEPENDENCIES ====
Other than the pygame module and the memory.py file mentioned above, there are two other source files this program depends on. They are named “gameBoard.py” and “gameMusic.py.”
• “gameBoard.py” sets up the game board and playing cards for display. It also reads files (images/fonts) from the “img” & “fnt “directory for use within this program.
• “gameMusic.py” sets up the game sounds and music. It also reads files (.ogg/.wav) from the “snd” directory for use within this program.
Both of these source files should be located in the same directory as “memory.py”
==== 4. FEATURES ====
This game features various colorful images and sounds for a pleasant user experience. By default, there are 27 playing cards (image size: 80×80) for use located in the “img” folder, and more can be added by the player in the future if they desire.
There are four attainable memory ranks available in this game, with two of them being displayed below. Play the full game to discover the rest!
Here are screenshots of the game during play. (on all images, click to enlarge)

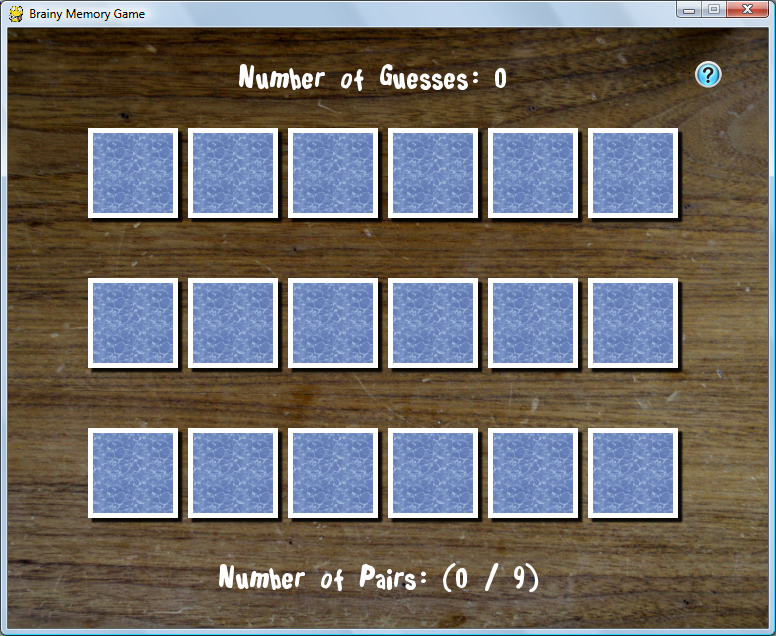
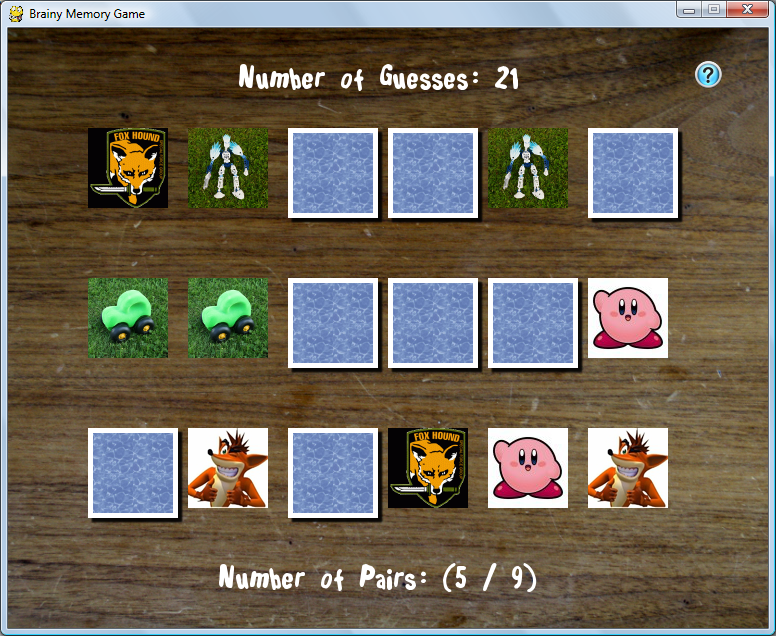
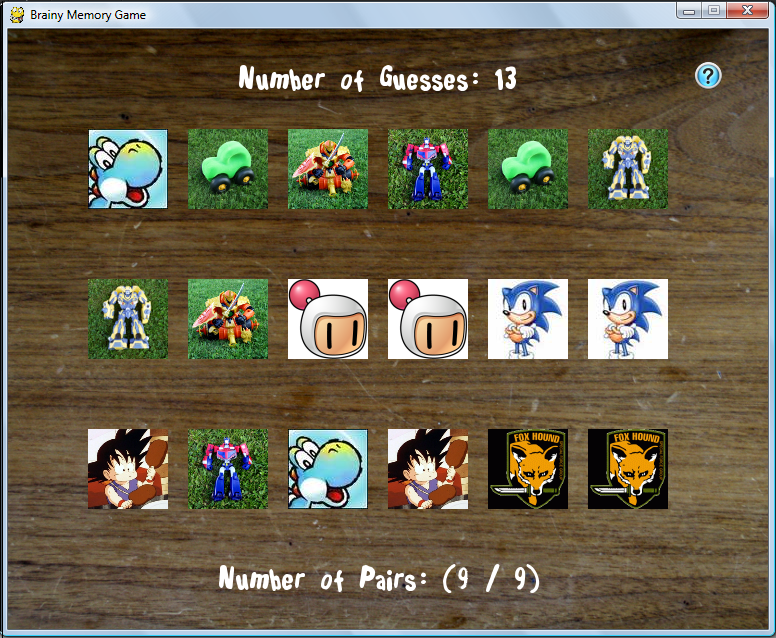
==== 5. DOWNLOAD AND PLAY ====
• Brainy Memory Game Source Code - Click Here To Download
• Brainy Memory Game Executable File - Click Here To Download
NOTE: Python and Pygame are not needed to play the executable file!
Python || Random Number Guessing Game Using Random MyRNG & While Loop

Here is another homework assignment which was presented in introduction class. The following is a simple guessing game using commandline arguments, which demonstrates the use of generating random numbers.
REQUIRED KNOWLEDGE FOR THIS PROGRAM
How To Get User Input
Getting Commandline Arguments
While Loops
MyRNG.py - Random Number Class
==== 1. DESCRIPTION ====
The following program is a simple guessing game which demonstrates how to generate random numbers using python. This program will seed the random number generator (located in the file MyRNG.py), select a number at random, and then ask the user for a guess. Using a while loop, the user will keep attempting to guess the selected random number until the correct guess is obtained, afterwhich the user will have the option of continuing play or exiting.
==== 2. USAGE ====
The user enters various options into the program via the commandline. An example of how the commandline can be used is given below.
python3 guess.py [-h] [-v] -s [seed] -m 2 -M 353
Where the brackets are meant to represent features which are optional, meaning the user does not have to specify them at run time.
The -m and -M options are mandatory.
• -M is best picked as a large prime integer
• -m is best picked as an integer in the range of 2,3,..,M-1
NOTE: The use of commandline arguments is not mandatory. If any of the mandatory options are not selected, the program uses its own logic to generate random numbers.
==== 3. FEATURES ====
The following lists and explains the command line argument options.
• -s (seed): Seed takes an integer as a parameter and is used to seed the random number generator. When omitted, the program uses its own logic to seed the generator
• -v (verbose): Turn on debugging messages.
• -h (help): Print out a help message which tells the user how to run the program and a brief description of the program.
• -m (minimum): Set the minimum of the range of numbers the program will select its numbers from.
• -M (maximum): Set the maximum of the range of numbers the program will select its numbers from.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 |
# ============================================================================= # Name: K Perkins # Date: Aug 6, 2013 # Taken From: http://programmingnotes.org/ # File: guess.py # Description: This is the guess.py module which uses a random number # generator to simulate a simple guessing game. This program will seed the # random number generator (located in the file MyRNG.py), select a number at # random, and then ask the user for a guess. The user will keep attempting # to guess the selected random number until the correct guess is obtained, # afterwhich the user will have the option of continuing play or exiting # ============================================================================= # Sample commandline: guess.py -s 3454 -m 1 -M 1000 import sys, pdb from MyRNG import * def Usage(status, msg = ""): # Function prints out usage directions aswell as a simple # message if a string is sent as a 2nd parameter if(msg): print(msg) print("nUSAGE:n ", sys.argv[0],"[-h help] [-v] [-s seed] [-m minimum number]", "[-M maximum number]") sys.exit(status) def IsWarmer(userGuess, numGuess, randomNumber): # Function determines if the current number the user guesses is closer # to the random number than the previous guess. # Function returns TRUE if current user guess is 'warmer' # than previous, otherwise returns FALSE currGuessDifference = userGuess[numGuess] - randomNumber currGuessDifference = math.fabs(currGuessDifference) prevGuessDifference = userGuess[numGuess-1] - randomNumber prevGuessDifference = math.fabs(prevGuessDifference) if(currGuessDifference < prevGuessDifference): return True else: return False def main(): # This is the 'main' function which first takes a string via the commandline # and parses it to determine various modes of operation, namely being # 'seed,' 'minimum,' and 'maximum.' After the commandline options # are obtained, that information is sent to the MyRNG class in order # to generate a random number. After a random number is found, using # a while loop, the user is prompted to try and guess that specified # number, repeatedly doing so until a correct guess is found # declare variables index = 0 # counter which is used to index the sys.argv string verbose = False choices = (("y"),("yes"),("n"),("no")) # This is to be used for the while loop seed = 806189064 # saves the seed from the command line minimum = 1 # saves the minimum num from the command line maximum = 1000 # saves the maximum num from the command line loop = True # this controls the while loop randomNumber = 0 # this saves the random number from the generator userGuess = [] # this saves the user guesses numGuess = 0 # this is the counter wgich keeps track of the num of usr guesses newGame = True # bool to determine if the user is playing a new game programDescr = """nDESCRIPTION: The following is a simple guessing game in which the user is prompted to guess a number and the computer determines if the guess is above, below or exactly the random number which was selected.""" # == determine if the user entered enough args via commandline == # if(len(sys.argv) < 1): #if not enough args, stop the program and print an error message Usage(1, "n** Must provide atleast 1 argument") # == parse thru the argv string to find the appropriate tokens == # for currentArg in sys.argv: if(currentArg == "-h"): # print out the usage message and exit. Usage(2, programDescr) elif(currentArg == "-v"): # set verbose mode to be true for debugging messages verbose = True elif(currentArg == "-s"): # set the seed here # if the user doesnt specify a seed, the # default is my CWID if((index+1 < len(sys.argv)) and (sys.argv[index+1].isdigit())): seed = int(sys.argv[index+1]) else: seed = 806189064 elif currentArg == "-m": # set the minimum here # if the user doesnt specify a min, the default is 1 if((index+1 < len(sys.argv)) and (sys.argv[index+1].isdigit())): minimum = int(sys.argv[index+1]) else: minimum = 1 elif currentArg == "-M": # set the maximum here # if the user doesnt specify a max, the default is 1000 if((index+1 < len(sys.argv)) and (sys.argv[index+1].isdigit())): maximum = int(sys.argv[index+1]) else: maximum = 1000 # increment the index counter index += 1 # print debugging messages if debug mode is on if(verbose): print ("nThis message only appears if verbose mode is turned on.") print (""" ** To continue seeing debugging messages, press the "n" button when prompted. To print the current value of variables, press the "p" button followed by the name of the variable you wish to print. Press the "l" button to visually see where you are in the programs souce code. To quit debugging, press the "c" button.n""") pdb.set_trace() print("nSeed = %d, Minimum = %d, Maximum = %d" %(seed, minimum, maximum)) # == declare the class object == # random = MyRNG(minimum, maximum) random.Seed(seed) randomNumber = random.Next() print("nI'm thinking of a number between %d and %d" ". Go ahead and make your first guess. " %(minimum, maximum)) # * this is the while loop which simulates a guessing game. # * the loop gets a number from the user and determines if the # user input is a "winner, warmer, or colder" in relation to the # random number which was generated. # * once the user guesses correctly, they have a choice of continuing # play or exiting the game. If they choose to play again, a new # random number is generated while(loop): userGuess.append(int(input(">> "))) if(newGame): newGame = False if((userGuess[numGuess] > randomNumber) or (userGuess[numGuess] < randomNumber)): print("nSorry that was not correct, please try again...n") elif((userGuess[numGuess] > randomNumber) or (userGuess[numGuess] < randomNumber)): if(IsWarmer(userGuess, numGuess, randomNumber)): print("nWARMERn") else: print("nCOLDERn") if(userGuess[numGuess] == randomNumber): print("nWINNER! You have guessed correctly!") print("It took you %d attempt(s) to find the answer!" %(numGuess+1)) del userGuess[:] numGuess = -1 answer = input("nWould you like to play again? (Yes or No): ") answer = answer.lower() if(answer in choices[:2]): randomNumber = random.Next() print("nMake a guess between %d and %dn" %(minimum, maximum)) newGame = True elif((answer in choices[2:]) or (answer not in choices[2:])): loop = False numGuess += 1 print("nThanks for playing!!") if __name__ == "__main__": main() # http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
Once compiled, you should get this as your output:
Seed = 806189064, Minimum = 1, Maximum = 1000I'm thinking of a number between 1 and 1000. Go ahead and make your first guess.
>> 500Sorry that was not correct, please try again...
>> 400
WARMER
>> 600
COLDER
>> 300
WARMER
>> 150
WARMER
>> 100
COLDER
>> 180
COLDER
>> 190
COLDER
>> 130
WARMER
>> 128
WINNER! You have guessed correctly!
It took you 10 attempt(s) to find the answer!Would you like to play again? (Yes or No): y
------------------------------------------------------------
Make a guess between 1 and 1000
>> 500
Sorry that was not correct, please try again...
>> 600
COLDER
>> 400
WARMER
>> 300
WARMER
>> 280
WARMER
>> 260
WARMER
>> 250
COLDER
>> 256
WINNER! You have guessed correctly!
It took you 8 attempt(s) to find the answer!Would you like to play again? (Yes or No): n
Thanks for playing!!
Python || Custom Random Number Generator Class MyRNG
The following is sample code for a simple random number generator class. This random number generator is based on the Park & Miller paper “Random Number Generators: Good Ones Are Hard To Find.”
This class has three functions. The constructor initializes data members “m_min” and “m_max” which stores the minimum and maximum range of values in which the random numbers will generate.
The “Seed()” function stores the value of the current seed within the class, and the “Next()” function returns a random number to the caller using an algorithm based on the Park & Miller paper listed in the paragraph above. Each time the “Next()” function is called, a new random number is generated and returned to the caller.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
# ============================================================================= # Author: K Perkins # Date: Aug 6, 2013 # Taken From: http://programmingnotes.org/ # File: MyRNG.py # Description: This is the MyRNG.py module which contains the class # declaration for the random number generator. This module recieves a # seed, minimum, and maximum number and generates a random number using # the "Next()" function. Each time the "Next()" function is called, a new # random number is generated and returned to the caller # ============================================================================= import math, time class MyRNG: # MyRNG class. This is the class declaration for the random number # generator. The constructor initializes data members "m_min" and # "m_max" which stores the minimum and maximum range of values in which # the random numbers will generate. There is another variable named "m_seed" # which is initialized using the method Seed(), and stores the value of the # current seed within the class. Using the obtained values from above, the # "Next()" method returns a random number to the caller using an algorithm # based on the Park & Miller paper "RANDOM NUMBER GENERATORS: GOOD ONES ARE # HARD TO FIND" def __init__(self, low = 0, high = 0): # The constructor initializes data members "m_min" and "m_max" if(low < 2): low = 2 if(high < 2): high = 9223372036854775807 self.m_min = low self.m_max = high self.m_seed = time.time() def Seed(self, seed): # Seed the generator with 'seed' self.m_seed = seed def Next(self): # Return the next random number using an algorithm based on the # Park & Miller paper "RANDOM NUMBER GENERATORS: GOOD ONES ARE # HARD TO FIND" a = self.m_min m = self.m_max q = math.trunc(m / a) r = m % a hi = self.m_seed / q lo = self.m_seed % q x = (a * lo) - (r * hi) if(x < a): x += a self.m_seed = x self.m_seed %= m # ensure that the random number is not less # than the minimum number within the user specified range if(self.m_seed < a): self.m_seed += a return int(self.m_seed) def test(): # Simple test function to see if the functionality of my class # is there and works random = MyRNG(7, 1987) random.Seed(806189064) for x in range(15): print("%d, " %(random.Next()), end = "") if __name__ == '__main__': test() # http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
===== DEMONSTRATION HOW TO USE =====
Use of the above class is very simple to use. A sample function demonstrating its use is provided on line #64 in the above code snippet.
After running the code, the following is sample output:
SAMPLE OUTPUT:
1037, 1296, 1123, 1900, 1375, 1676, 1798, 662, 664, 674, 746, 1249, 793, 1578, 1112,
Python || Pdf Merge Using PyPdf

The following is a simple pdf file merger program which utilizes the “pyPdf” library to manipulate pdf files. This program has the ability to merge entire selected pdf files together, and save the selected files into one single new pdf file.
REQUIRED KNOWLEDGE FOR THIS PROGRAM
PyPdf - What Is It?
How To Create Executable Python Programs
Display The Time In Python
Metadata With PyPdf
Pdf Merge Executable File - Click Here To Download
This program first asks the user to place the pdf file(s) they wish to merge into a specified folder. The default input folder is titled “Files To Merge.” After the input pdf file(s) have been placed into the specified input folder, the program prompts the user to select which file(s) they wish to merge together. As soon as the input pdf file(s) have been selected, the file merging begins, with the files being saved to the output pdf file in the exact same order as specified by the user. As soon as the file merging is complete, the single merged pdf file is saved into an output folder titled “Completed Merged Files.”
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 |
# ============================================================================= # Author: K Perkins # Date: Aug 5, 2013 # Taken From: http://programmingnotes.org/ # File: PdfMerge.py # Description: This is a simple program utilizing the pyPdf library to # manipulate pdf files. This program has the ability to merge entire # selected pdf files together, and save the selected files into one # single new pdf file. # ============================================================================= import sys, os, datetime, platform from pyPdf.pdf import PdfFileWriter, PdfFileReader from pyPdf.generic import NameObject, createStringObject # ---- START GLOBAL VARIABLES ---- # INPUT_FILE_FOLDER = "Files To Merge" OUTPUT_FILE_FOLDER = "Completed Merged Files" OUTPUT_FILE_NAME = "Merged File.pdf" PDF_PRODUCER = "KENNETH'S PDF MERGER" # Determine the platform if(platform.system() == "Windows"): CURRENT_USER = os.environ.get("USERNAME") else: CURRENT_USER = os.environ.get("USER") # ---- END GLOBAL VARIABLES ---- # def DoesFileExists(fileName, fileFolder): # determine if a file exists try: filePath = os.path.join(fileFolder, fileName) with open(filePath) as f: pass return True except IOError as e: return False def DoesFolderExist(fileFolder): # determine if a folder exists if not os.path.exists(fileFolder): os.makedirs(fileFolder) return False return True def CheckOutFileDigits(outfile): # check if a file already exists in a folder char = outfile[len(outfile)-1] if(char == ")"): return True return False def GetPageNumbers(pageRange): # parse a page range (i.e: 1,2,5,56-100,241) and return its # integer equivalent pageIndex = 0 inDigit = False inNums2 = False nums = "" nums2 = "" fileNumbers = [] while(pageIndex < len(pageRange)): if(pageRange[pageIndex].isdigit()): inDigit = True else: inDigit = False if(inDigit): if(inNums2 == False): nums += pageRange[pageIndex] else: nums2 += pageRange[pageIndex] else: if(nums != "" and pageRange[pageIndex] == "," and inNums2 == False): fileNumbers.append(int(nums)) nums = "" elif(nums != "" and pageRange[pageIndex] == "-"): inNums2 = True elif(nums2 != "" and inNums2): for x in range(int(nums), int(nums2)+1): fileNumbers.append(x) nums = "" nums2 = "" inNums2 = False elif((nums != "" and pageRange[pageIndex] != ",") or (nums != "" and pageRange[pageIndex] != "-")): fileNumbers.append(int(nums)) nums = "" pageIndex += 1 # DO THIS IF NUMBERS ARE LEFT OVER FROM THE ABOVE LOOP ^ if(nums != "" and nums2 != ""): for x in range(int(nums), int(nums2)+1): fileNumbers.append(x) elif(nums != ""): fileNumbers.append(int(nums)) return fileNumbers def DisplayFiles(files): # display files in a folder numFiles = 1 print("Index # ||tFile Namen"+ "-----------------------------------") for x in files: print("(%d) t ||t%s" %(numFiles, x)) numFiles += 1 def GetFileName(index, files): # return the filename from the input folder return files[index] def Cls(): # clear the console screen os.system(["clear","cls"][platform.system()=="Windows"]) def GetFiles(): # prompt the user to enter files into the input folder while(len(os.listdir(INPUT_FILE_FOLDER)) < 1): print("** NOTE: To continue, please place the file(s) that you wish to "+ "nmerge inside the "%s" folder located in:" %(INPUT_FILE_FOLDER)) print("n%s%s" %(os.getcwd(), INPUT_FILE_FOLDER)) input("nPlease press ENTER to continue...") Cls() # clear the console screen def main(): # declare variables input_pdfFile = "" output_pdfFile = PdfFileWriter() files = [] index = 0 outfileName = "" numPages = 0 pageRange = "" fileNumbers = [] removePage = [] errorPage = False # CHECK TO SEE IF INPUT/OUTPUT FOLDERS EXIST, CREATE THEM IF THEY DONT DoesFolderExist(INPUT_FILE_FOLDER) DoesFolderExist(OUTPUT_FILE_FOLDER) # GET FILE NAMES FROM THE USER TO MERGE TOGETHER while(len(files) < 1): Cls() fileNumbers = [] removePage = [] while(len(fileNumbers) < 1): # MAKE SURE THERE ARE FILES IN THE INPUT FOLDER errorPage = False if(len(os.listdir(INPUT_FILE_FOLDER)) < 1): GetFiles() print("nThese are the files thats currently located in "+ "the "%s" folder..n" %(INPUT_FILE_FOLDER)) # DISPLAY THE FILES THATS IN THE INPUT FOLDER TO THE SCREEN DisplayFiles(os.listdir(INPUT_FILE_FOLDER)) # ASK THE USER FOR FILES NAMES/INDEXES print("nPlease enter the index numbers of the files that " +"you wish to merge together:") print("Example: 1,2,5,56-100,241") pageRange = input(">> ") # REMOVE WHITESPACES FROM THE STRING pageRange = pageRange.replace(" ", "") print("nYou have selected to merge the file(s): %s" %(pageRange)) # GET THE TOTAL NUMBER OF FILES FROM THE USER AS SPECIFIED FROM ABOVE fileNumbers = GetPageNumbers(pageRange) # FIND ANY FILES FROM THE LIST WHICH DONT EXIST IN THE FOLDER for x in fileNumbers: if((x > len(os.listdir(INPUT_FILE_FOLDER))) or (x < 1)): errorPage = True removePage.append(x) # REMOVE ALL FILE INDEX NUMBERS THAT DONT EXIST IN THE FOLDER for x in removePage: fileNumbers.remove(x) # CHECK IF THERE ARE ANY VALID FILES TO BE MERGED FROM THE FOLDER if(len(fileNumbers) < 1): print("n----------------------------------------------------------") print("n** ERROR: No files have been selected to be merged!") input("nPlease press ENTER to continue...") Cls() else: for x in fileNumbers: files.append(GetFileName(x-1, os.listdir(INPUT_FILE_FOLDER))) if(errorPage): print("n----------------------------------------------------------") print("n** ERROR: The folder "%s" only contains %d files!n" %(INPUT_FILE_FOLDER, len(os.listdir(INPUT_FILE_FOLDER)))) print("Invalid file index numbers have been detected") input("nPlease press ENTER to continue...") removePage = [] print("n----------------------------------------------------------") print("nThe following files have been selected to be merged!n") DisplayFiles(files) # IF ALL ABOVE IS OK, CHECK IF THE SELECTED INPUT FILES ARE PDF FILES for x in files: if(x.endswith(".pdf") == False): removePage.append(x) errorPage = True # REMOVE ALL THE FILES THAT ARENT PDF FILES if(errorPage): print("n** ERROR: Sorry, but the files listed below are " + "not pdf files and cannot be merged..n") index = 1 for x in removePage: files.remove(x) print("(%d) t"%s"" %(index, x)) index += 1 if(len(files) < 1): input("nPlease press ENTER to continue...") input("nPlease press ENTER to continue...") print("n----------------------------------------------------------n") # IF ALL IS OK, MERGE THE EXISITING FILES TOGETHER for x in range(0, len(files)): filePath = os.path.join(INPUT_FILE_FOLDER, files[x]) input_pdfFile = PdfFileReader(open(filePath, "rb")) print("%s has %d pages." % (files[x], input_pdfFile.getNumPages())) for y in range(input_pdfFile.getNumPages()): output_pdfFile.addPage(input_pdfFile.getPage(y)) # CONSTRUCT AN OUTPUT FILENAME outfileName = files[0][:-4] +" - "+ OUTPUT_FILE_NAME while(DoesFileExists(outfileName, OUTPUT_FILE_FOLDER)): outfileName = outfileName[:-4] # remove ".pdf" # do this if there is already 2 copies of the outfile if(CheckOutFileDigits(outfileName)): outfileName = outfileName[:-1]# remove ")" count = int(outfileName[len(outfileName)-1]) # get num count += 1 outfileName = outfileName[:-1]# remove num outfileName += str(count)+")"# add new incremented num # do this if outfile exists only once else: outfileName += " ("+str(2)+")" outfileName += ".pdf" # GET THE NUMBER OF PAGES IN THE OUTPUT PDF FILE numPages = output_pdfFile.getNumPages() # SAVE OUTPUT FILE TO THE OUTPUT FOLDER now = datetime.datetime.now() time = str(now.strftime("CREATED: %m/%d/%Y, %I:%M:%S %p")) infoDict = output_pdfFile._info.getObject() infoDict.update({ NameObject('/Title'): createStringObject(outfileName), NameObject('/Author'): createStringObject(CURRENT_USER), NameObject('/Subject'): createStringObject(time), NameObject('/Creator'): createStringObject(PDF_PRODUCER) }) filePath = os.path.join(OUTPUT_FILE_FOLDER, outfileName) outputStream = open(filePath, "wb") output_pdfFile.write(outputStream) outputStream.close() # DISPLAY FINAL MESSAGE TO USER print("n"%s" has been created and contains %d total page(s)" %(outfileName, numPages)) print("nThis file is located in the following directory:n" +"n%s%s" %(os.getcwd(), OUTPUT_FILE_FOLDER)) input("nPlease press ENTER to continue...") if __name__ == "__main__": main() # http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
Click here to download a Windows executable file demonstrating the above use.
Python || Pdf Split & Extract Using PyPdf

The following is a simple pdf file split & extractor program which utilizes the “pyPdf” library to manipulate pdf files. This program has the ability to extract selected pages from an existing pdf file, and save the extracted pages into a new pdf file.
REQUIRED KNOWLEDGE FOR THIS PROGRAM
PyPdf - What Is It?
How To Create Executable Python Programs
Display The Time In Python
Metadata With PyPdf
Pdf Split Executable File - Click Here To Download
This program first asks the user to place the pdf file(s) they wish to extract pages from into a specified folder. The default input folder is titled “Files To Extract.” After the input pdf file(s) have been placed into the specified input folder, the program prompts the user to select which file they wish to extract pages from. As soon as an input pdf file has been selected, the user is asked to enter in the page numbers they wish to extract from the specified input pdf file. After the page extraction is completed, the selected pages are merged into one single pdf file, and is saved into an output folder titled “Completed Extracted Files.”
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 |
# ============================================================================= # Author: K Perkins # Date: Aug 4, 2013 # Taken From: http://programmingnotes.org/ # File: PdfSplit.py # Description: This is a simple program utilizing the pyPdf library to # manipulate pdf files. This program has the ability to extract selected # pages from an existing pdf file, and save the extracted pages into # a new pdf file. # ============================================================================= import sys, os, datetime, platform from pyPdf.pdf import PdfFileWriter, PdfFileReader from pyPdf.generic import NameObject, createStringObject # ---- START GLOBAL VARIABLES ---- # INPUT_FILE_FOLDER = "Files To Extract" OUTPUT_FILE_FOLDER = "Completed Extracted Files" OUTPUT_FILE_NAME = "Extracted File.pdf" PDF_PRODUCER = "KENNETH'S PDF EXTRACTOR" # Determine the platform if(platform.system() == "Windows"): CURRENT_USER = os.environ.get("USERNAME") else: CURRENT_USER = os.environ.get("USER") # ---- END GLOBAL VARIABLES ---- # def DoesFileExists(fileName, fileFolder): # determine if a file exists try: filePath = os.path.join(fileFolder, fileName) with open(filePath) as f: pass return True except IOError as e: return False def DoesFolderExist(fileFolder): # determine if a folder exists if not os.path.exists(fileFolder): os.makedirs(fileFolder) return False return True def CheckOutFileDigits(outfile): # check if a file already exists in a folder char = outfile[len(outfile)-1] if(char == ")"): return True return False def GetPageNumbers(pageRange): # parse a page range (i.e: 1,2,5,56-100,241) and return its # integer equivalent pageIndex = 0 inDigit = False inNums2 = False nums = "" nums2 = "" pageNumbers = [] while(pageIndex < len(pageRange)): if(pageRange[pageIndex].isdigit()): inDigit = True else: inDigit = False if(inDigit): if(inNums2 == False): nums += pageRange[pageIndex] else: nums2 += pageRange[pageIndex] else: if(nums != "" and pageRange[pageIndex] == "," and inNums2 == False): pageNumbers.append(int(nums)) nums = "" elif(nums != "" and pageRange[pageIndex] == "-"): inNums2 = True elif(nums2 != "" and inNums2): for x in range(int(nums), int(nums2)+1): pageNumbers.append(x) nums = "" nums2 = "" inNums2 = False elif((nums != "" and pageRange[pageIndex] != ",") or (nums != "" and pageRange[pageIndex] != "-")): pageNumbers.append(int(nums)) nums = "" pageIndex += 1 # DO THIS IF NUMBERS ARE LEFT OVER FROM THE ABOVE LOOP ^ if(nums != "" and nums2 != ""): for x in range(int(nums), int(nums2)+1): pageNumbers.append(x) elif(nums != ""): pageNumbers.append(int(nums)) return pageNumbers def DisplayFiles(files): # display files in a folder numFiles = 1 print("Index # ||tFile Namen"+ "-----------------------------------") for x in files: print("(%d) t ||t%s" %(numFiles, x)) numFiles += 1 def GetFileName(index, files): # return the filename from the input folder return files[index] def Cls(): # clear the console screen os.system(["clear","cls"][platform.system()=="Windows"]) def GetFiles(): # prompt the user to enter files into the input folder while(len(os.listdir(INPUT_FILE_FOLDER)) < 1): print("** NOTE: To continue, please place the file(s) that you wish to "+ "nextract pages from inside the "%s" folder located in:" %(INPUT_FILE_FOLDER)) print("n%s%s" %(os.getcwd(), INPUT_FILE_FOLDER)) input("nPlease press ENTER to continue...") Cls() # clear the console screen def main(): # declare variables fileName = "" currFile = "" outfileName = "" input_pdfFile = "" output_pdfFile = PdfFileWriter() numPages = 0 numPagesInPDF = 0 pageRange = "" pageNumbers = [] removePage = [] errorPage = False initial = "" Cls() # CHECK TO SEE IF INPUT/OUTPUT FOLDERS EXIST, CREATE THEM IF THEY DONT DoesFolderExist(INPUT_FILE_FOLDER) DoesFolderExist(OUTPUT_FILE_FOLDER) # GET A FILE NAME FROM USER TO EXTRACT PAGES FROM while(fileName == ""): while(initial.isdigit() == False): # MAKE SURE THERE ARE FILES IN THE INPUT FOLDER if(len(os.listdir(INPUT_FILE_FOLDER)) < 1): GetFiles() print("nThese are the files thats currently located in "+ "the "%s" folder..n" %(INPUT_FILE_FOLDER)) # DISPLAY THE FILES THATS IN THE INPUT FOLDER TO THE SCREEN DisplayFiles(os.listdir(INPUT_FILE_FOLDER)) # GET THE FILE INDEX NUMBER FROM THE USER initial = input("nPlease enter the index number of the file that " +"you wish to extract pages from:n>> ") # CHECK IF THE USER ENTERED A DIGIT OR NOT if(initial.isdigit()): fileIndex = abs(int(initial)) # CHECK IF THE DIGIT IS WITHIN A VALID INDEX RANGE if((fileIndex > len(os.listdir(INPUT_FILE_FOLDER))) or (fileIndex <= 0)): print("nSorry, but "%d" is not a valid index number..." %(fileIndex)) input("nPlease press ENTER to continue...") Cls() # clear the console screen initial = "" fileIndex = "" # GET THE FILENAME FROM THE FOLDER else: currFile = GetFileName(fileIndex-1, os.listdir(INPUT_FILE_FOLDER)) else: print("nSorry, but "%s" is not a positive digit..." "nPlease enter positive digits only!" %(initial)) input("nPlease press ENTER to continue...") Cls() # CHECK IF ITS A PDF FILE if(currFile.endswith(".pdf")): fileName = currFile else: print("nSorry, but "%s" is not a pdf file!" %(currFile)) input("nPlease press ENTER to continue...") Cls() # clear the console screen initial = "" # GET INPUT FILE DOCUMENT INFO filePath = os.path.join(INPUT_FILE_FOLDER, fileName) input_pdfFile = PdfFileReader(open(filePath, "rb")) numPagesInPDF = input_pdfFile.getNumPages() # DISPLAY DIRECTIONS TO USER print("nCurrent file = "%s" and contains %d page(s)" %(currFile, numPagesInPDF)) print("nPlease enter the page numbers you wish to extract," +" separated by commas") print("Example: 1,2,5,56-100,241") pageRange = input(">> ") # REMOVE WHITESPACES FROM THE STRING pageRange = pageRange.replace(" ", "") print("nYou have selected to extract page(s): %s" %(pageRange)) print("n----------------------------------------------------------") # GET THE TOTAL NUMBER OF PAGES FROM THE USER AS SPECIFIED FROM ABOVE pageNumbers = GetPageNumbers(pageRange) # FIND ANY PAGE NUMBERS FROM THE LIST WHICH DONT EXIST IN THE FILE for x in pageNumbers: if((x > numPagesInPDF) or (x < 1)): errorPage = True removePage.append(x) # REMOVE ALL PAGE NUMBERS THAT DONT EXIST for x in removePage: pageNumbers.remove(x) # CHECK IF THERE ARE ANY VALID PAGES TO BE EXTRACTED FROM THE PDF FILE if(len(pageNumbers) < 1): print("n** ERROR: No pages have been selected to extract!n" +"Exiting...") input("nPlease press ENTER to continue...") sys.exit() # DISPLAY ERROR IF A PAGE NUMBER DOESNT EXIST IN PDF DOCUMENT elif(errorPage): print("n** ERROR: "%s" only contains %d page(s).nThe pages selected " "after page #%d cannot be extracted from "%s"" %(currFile,numPagesInPDF,numPagesInPDF,currFile)) print("nOnly page(s)",pageNumbers,"will be extracted from the file!") input("nPlease press ENTER to continue...") print("n----------------------------------------------------------") # START EXTRACTING PAGE NUMBERS # GET SELECTED PAGES FROM THE INPUT FILE for x in pageNumbers: output_pdfFile.addPage(input_pdfFile.getPage(x-1)) # CONSTRUCT OUTPUT FILENAME outfileName = fileName[:-4] +" - "+ OUTPUT_FILE_NAME while(DoesFileExists(outfileName, OUTPUT_FILE_FOLDER)): outfileName = outfileName[:-4] # remove ".pdf" # do this if there is already 2 copies of the outfile if(CheckOutFileDigits(outfileName)): outfileName = outfileName[:-1]# remove ")" count = int(outfileName[len(outfileName)-1]) # get num count += 1 outfileName = outfileName[:-1]# remove num outfileName += str(count)+")"# add new incremented num # do this if outfile exists only once else: outfileName += " ("+str(2)+")" outfileName += ".pdf" # GET THE NUMBER OF PAGES IN THE OUTPUT PDF FILE numPages = output_pdfFile.getNumPages() # SAVE OUTPUT FILE TO THE OUTPUT FOLDER now = datetime.datetime.now() time = str(now.strftime("CREATED: %m/%d/%Y, %I:%M:%S %p")) infoDict = output_pdfFile._info.getObject() infoDict.update({ NameObject('/Title'): createStringObject(outfileName), NameObject('/Author'): createStringObject(CURRENT_USER), NameObject('/Subject'): createStringObject(time), NameObject('/Creator'): createStringObject(PDF_PRODUCER) }) filePath = os.path.join(OUTPUT_FILE_FOLDER, outfileName) outputStream = open(filePath, "wb") output_pdfFile.write(outputStream) outputStream.close() # DISPLAY FINAL MESSAGE TO USER print("n"%s" has been created and contains %d total page(s)" %(outfileName, numPages)) print("nThis file is located in the following directory:n" +"n%s%s" %(os.getcwd(), OUTPUT_FILE_FOLDER)) input("nPlease press ENTER to continue...") if __name__ == "__main__": main() # http://programmingnotes.org/ |
QUICK NOTES:
The highlighted lines are sections of interest to look out for.
The code is heavily commented, so no further insight is necessary. If you have any questions, feel free to leave a comment below.
Click here to download a Windows executable file demonstrating the above use.







